在不同的情况下(比如使用不同的OCR引擎插件), 图片识别接口 可以传入不同的参数。
通过 参数查询接口 ,可以获取所有参数的定义、默认值、可选值等信息。
你可以手动调用查询接口来确认信息,也可以通过查询接口返回的字典来自动化生成前端UI。
URL:/api/ocr/get_options
例:http://127.0.0.1:1224/api/ocr/get_options
(默认端口为1224,可以在 Umi-OCR 全局设置中更改。)
方法:GET
返回一个json字符串,记录 图片OCR接口 的参数定义。
以PaddleOCR引擎插件为例,返回值格式化后为:(点击展开)
{
"ocr.language": {
"title": "语言/模型库",
"optionsList": [
["models/config_chinese.txt","简体中文"],
["models/config_en.txt","English"],
["models/config_chinese_cht(v2).txt","繁體中文"],
["models/config_japan.txt","日本語"],
["models/config_korean.txt","한국어"],
["models/config_cyrillic.txt","Русский"]
],
"type": "enum",
"default": "models/config_chinese.txt"
},
"ocr.cls": {
"title": "纠正文本方向",
"default": false,
"toolTip": "启用方向分类,识别倾斜或倒置的文本。可能降低识别速度。",
"type": "boolean"
},
"ocr.limit_side_len": {
"title": "限制图像边长",
"optionsList": [
[960,"960 (默认)"],
[2880,"2880"],
[4320,"4320"],
[999999,"无限制"]
],
"toolTip": "将边长大于该值的图片进行压缩,可以提高识别速度。可能降低识别精度。",
"type": "enum",
"default": 960
},
"tbpu.parser": {
"title": "排版解析方案",
"toolTip": "按什么方式,解析和排序图片中的文字块",
"default": "multi_para",
"optionsList": [
["multi_para","多栏-按自然段换行"],
["multi_line","多栏-总是换行"],
["multi_none","多栏-无换行"],
["single_para","单栏-按自然段换行"],
["single_line","单栏-总是换行"],
["single_none","单栏-无换行"],
["single_code","单栏-保留缩进"],
["none","不做处理"]
],
"type": "enum"
},
"tbpu.ignoreArea": {
"title": "忽略区域",
"toolTip": "数组,每一项为[[左上角x,y],[右下角x,y]]。",
"default": [],
"type": "var"
},
"data.format": {
"title": "数据返回格式",
"toolTip": "返回值字典中,[\"data\"] 按什么格式表示OCR结果数据",
"default": "dict",
"optionsList": [
["dict","含有位置等信息的原始字典"],
["text","纯文本"]
],
"type": "enum"
}
}返回值中,每个参数有这些属性:
title:参数名称。toolTip:参数说明。default:默认值。type:参数值的类型,具体如下:enum:枚举。参数值必须为optionsList中某一项的[0]。boolean:布尔。参数值必须为true/false。text:字符串。number:数字。如何属性isInt==true,那么必须为整数。var:特殊类型,具体见toolTip的说明。
所有参数都是可选的。任一参数不填时,将被设为默认值。
| 键 | 默认值 | 类型 | 说明 |
|---|---|---|---|
ocr.language |
"models/config_chinese.txt" |
枚举,可选值为字符串:"models/config_chinese.txt"、 "models/config_en.txt"、 "models/config_chinese_cht(v2).txt"、 "models/config_japan.txt"、 "models/config_korean.txt"、 "models/config_cyrillic.txt" |
语言/模型库:加载 ./UmiOCR-data/plugins/PaddleOCR-json/models目录中的引擎配置文件,可切换不同语言的配置。注意,此参数仅适用于PaddleOCR引擎插件!其他OCR引擎请自行调用参数查询接口获取。 |
ocr.cls |
false |
布尔,可选true/false |
纠正文本方向:填true时启用方向分类,识别倾斜或倒置的文本。可能降低识别速度。注意,仅适用于PaddleOCR! |
ocr.limit_side_len |
960 |
枚举,可选值为整数: 960、 2880、 4320、 999999 |
限制图像边长:将边长大于该值的图片进行压缩。较低的限制值可以提高识别速度,较高的限制可以提高大图的识别精度。注意,仅适用于PaddleOCR! |
tbpu.parser |
"multi_para" |
枚举,可选值为字符串:"multi_para"、 "multi_line"、 "multi_none"、 "single_para"、 "single_line"、 "single_none"、 "single_code"、 "none" |
排版解析方案:按什么方式,解析和排序图片中的文字块。可选值的含义请见上方折叠内容tbpu.parser块的optionsList。 |
tbpu.ignoreArea |
[] |
嵌套整数列表 | 忽略区域:处于任意一个忽略区域内的OCR文本块将被舍弃。每个忽略区域用矩形坐标[[左上角x,y],[右下角x,y]]表示,详细见下个段落。 |
data.format |
"dict" |
枚举,可选值为字符串: dict、 text |
数据返回格式:返回值字典中,["data"] 按什么格式表示OCR结果数据。dict表示含有位置等信息的详细字典,text表示仅返回识别文本。 |
- 关于忽略区域
tbpu.ignoreArea:- 示例:假设忽略区域包含3个矩形框,那么
tbpu.ignoreArea的格式类似:[ [[0,0],[100,50]], // 第1个框,左上角(0,0),右下角(100,50) [[0,60],[200,120]], // 第2个 [[400,0],[500,30]] // 第3个 ]
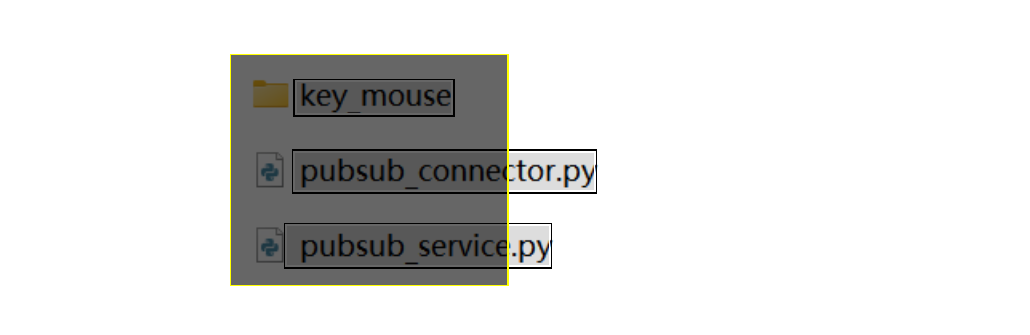
- 注意,完全处于忽略区域框内部的整个文本块(而不是单个字符)会被忽略。如下图所示,黄色边框的深色矩形是一个忽略区域。那么只有
key_mouse才会被忽略。pubsub_connector.py、pubsub_service.py这两个文本块得以保留。
- 示例:假设忽略区域包含3个矩形框,那么
对于上述返回值示例,可以组装出这样的参数字典:
{
"ocr.language": "models/config_chinese.txt",
"ocr.cls": true,
"ocr.limit_side_len": 4320,
"tbpu.parser": "multi_none",
"data.format": "text",
"tbpu.ignoreArea": [[[0,0],[100,50]], [[0,60],[200,120]]]
}JavaScript 示例:(点击展开)
const url = "http://127.0.0.1:1224/api/ocr/get_options";
fetch(url, {
method: "GET",
headers: { "Content-Type": "application/json" },
})
.then(response => response.json())
.then(data => { console.log(data); })
.catch(error => { console.error(error); });Python 示例:(点击展开)
import json, requests
response = requests.get("http://127.0.0.1:1224/api/ocr/get_options")
res_dict = json.loads(response.text)
print(json.dumps(res_dict, indent=4, ensure_ascii=False))手动调用:
- 确保 Umi-OCR 已在运行。
- 浏览器访问 http://127.0.0.1:1224/api/ocr/get_options
- 复制全部内容,粘贴到 在线JSON解析工具 里转换为可读文本。
传入一个base64编码的图片,返回OCR识别结果。
URL:/api/ocr
例:http://127.0.0.1:1224/api/ocr
方法:POST
参数:json字符串,内容为一个字典,键值为:
- base64 : 必填。待识别图像的 Base64 编码字符串,无需
data:image/png;base64,等前缀。 - options :可选。参数字典,见 查询接口 。
POST 参数示例:
{
"base64": "iVBORw0KGgoAAAAN……",
"options": {
"ocr.language": "models/config_chinese.txt",
"ocr.cls": true,
"ocr.limit_side_len": 4320,
"tbpu.parser": "multi_none",
"data.format": "text"
}
}返回json字符串,内容为一个字典,键值为::
| 字段 | 类型 | 描述 |
|---|---|---|
| code | int | 任务状态码。100为成功,101为无文本,其余为失败 |
| data | list/string | 识别结果,格式见下 |
| time | double | 识别耗时(秒) |
| timestamp | double | 任务开始时间戳(秒) |
图片中无文本(code==101),或识别失败(code!=100 and code!=101)时:
["data"]为string,内容为错误原因。例:{"code": 902, "data": "向识别器进程传入指令失败,疑似子进程已崩溃"}
识别成功(code==100)时,如果options中data.format为dict(默认值):
["data"]为list,每一项元素为dict,包含以下子元素:
| 参数名 | 类型 | 描述 |
|---|---|---|
| text | string | 文本 |
| score | double | 置信度 (0~1) |
| box | list | 文本框顺时针四个角的xy坐标:[左上,右上,右下,左下] |
| end | string | 表示本行文字结尾的结束符,根据排版解析得出。可能为空、空格 、换行\n。将所有OCR文本块拼接为完整段落时,按照 本行文字+本行结束符+下一行文字+下一行结束符+……的形式,就能恢复段落结构。 |
结果示例:
{
"code": 100,
"data": [
{
"text": "第一行的文本,",
"score": 0.99800001,
"box": [[x1,y1], [x2,y2], [x3,y3], [x4,y4]],
"end": "\n",
},
{
"text": "第二行的文本",
"score": 0.97513333,
"box": [[x1,y1], [x2,y2], [x3,y3], [x4,y4]],
"end": "",
},
]
}识别成功(code==100)时,如果options中data.format为text:
["data"]为string,即所有OCR结果的拼接。例:
"data": "第一行的文本,\n第二行的文本"- 为了确保兼容性,返回值json字符串经过了转义,非英文字符被转换为
\uXXXX形式的Unicode码点。使用任意编程语言的json库将其解析后,即可得到可读原文。 - 返回值json字符串中可能存在转义后的换行符
\\n(即\+n)来表达OCR段落结构。在某些语言的http库中,可能会自动将请求结果字符串中的转义换行符转换为真实换行,这会导致后续json解析失败。如果遇到这种情况,可以尝试先获取返回结果字符串,将其中所有真实换行\n替换为转义换行\\n,确保整个字符串中不存在真实换行;再交给json解析。
JavaScript 示例:(点击展开)
const url = 'http://127.0.0.1:1224/api/ocr';
const data = {
base64: "iVBORw0KGgoAAAANSUhEUgAAAC4AAAAXCAIAAAD7ruoFAAAACXBIWXMAABnWAAAZ1gEY0crtAAAAEXRFWHRTb2Z0d2FyZQBTbmlwYXN0ZV0Xzt0AAAHjSURBVEiJ7ZYrcsMwEEBXnR7FLuj0BPIJHJOi0DAZ2qSsMCxEgjYrDQqJdALrBJ2ASndRgeNI8ledutOCLrLl1e7T/mRkjIG/IXe/DWBldRTNEoQSpgNURe5puiiaJehrMuJSXSTgbaby0A1WzLrCCQCmyn0FwoN0V06QONWAt1nUxfnjHYA8p65GjhDKxcjedVH6JOejBPwYh21eE0Wzfe0tqIsEkGXcVcpoMH4CRZ+P0lsQp/pWJ4ripf1XFDFe8GHSHlYcSo9Es31t60RdFlN1RUmrma5oTzTVB8ZUaeeYEC9GmL6kNkDw9BANAQYo3xTNdqUkvHq+rYhDKW0Bj3RSEIpmyWyBaZaMTCrCK+tJ5Jsa07fs3E7esE66HzralRLgJKp0/BD6fJRSxvmDsb6joqkcFXGqMVVFFEHDL2gTxwCAaTabnkFUWhDCHTd9iYrGcAL1ZnqIp5Vpiqh7bCfua7FA4qN0INMcN1+cgCzj+UFxtbmvwdZvGIrI41JiqhZBWhhF8WxorkYPpQwJiWYJeA3rXE4hzcwJ+B96F9zCFHC0FcVegghvFul7oeEE8PvHeJqC0w0AUbbFIT8JnEwGbPKcS2OxU3HMTqD0r4wgEIuiKJ7i4MS16+og8/+bPZRPLa+6Ld2DSzcAAAAASUVORK5CYII=",
// 可选参数示例
"options": {
"data.format": "text",
}
};
fetch(url, {
method: "POST", body: JSON.stringify(data),
headers: {"Content-Type": "application/json"},
})
.then(response => response.json())
.then(data => {
console.log(data);
})
.catch(error => {
console.error(error);
});Python 示例:(点击展开)
import requests
import json
url = "http://127.0.0.1:1224/api/ocr"
data = {
"base64": "iVBORw0KGgoAAAANSUhEUgAAAC4AAAAXCAIAAAD7ruoFAAAACXBIWXMAABnWAAAZ1gEY0crtAAAAEXRFWHRTb2Z0d2FyZQBTbmlwYXN0ZV0Xzt0AAAHjSURBVEiJ7ZYrcsMwEEBXnR7FLuj0BPIJHJOi0DAZ2qSsMCxEgjYrDQqJdALrBJ2ASndRgeNI8ledutOCLrLl1e7T/mRkjIG/IXe/DWBldRTNEoQSpgNURe5puiiaJehrMuJSXSTgbaby0A1WzLrCCQCmyn0FwoN0V06QONWAt1nUxfnjHYA8p65GjhDKxcjedVH6JOejBPwYh21eE0Wzfe0tqIsEkGXcVcpoMH4CRZ+P0lsQp/pWJ4ripf1XFDFe8GHSHlYcSo9Es31t60RdFlN1RUmrma5oTzTVB8ZUaeeYEC9GmL6kNkDw9BANAQYo3xTNdqUkvHq+rYhDKW0Bj3RSEIpmyWyBaZaMTCrCK+tJ5Jsa07fs3E7esE66HzralRLgJKp0/BD6fJRSxvmDsb6joqkcFXGqMVVFFEHDL2gTxwCAaTabnkFUWhDCHTd9iYrGcAL1ZnqIp5Vpiqh7bCfua7FA4qN0INMcN1+cgCzj+UFxtbmvwdZvGIrI41JiqhZBWhhF8WxorkYPpQwJiWYJeA3rXE4hzcwJ+B96F9zCFHC0FcVegghvFul7oeEE8PvHeJqC0w0AUbbFIT8JnEwGbPKcS2OxU3HMTqD0r4wgEIuiKJ7i4MS16+og8/+bPZRPLa+6Ld2DSzcAAAAASUVORK5CYII=",
# 可选参数示例
"options": {
"data.format": "text",
}
}
headers = {"Content-Type": "application/json"}
data_str = json.dumps(data)
response = requests.post(url, data=data_str, headers=headers)
response.raise_for_status()
res_dict = json.loads(response.text)
print(res_dict)