相关链接: AI技术原理
- marktechpost
- 3Blue1Brown
- dair-ai
- https://theresanaiforthat.com/
- 人工智能杂志
- 抱抱脸每日论文
- 机器学习大师
- Methods for adapting large language models
- https://ai.meta.com/blog/how-to-fine-tune-llms-peft-dataset-curation/
- 《人工智能杂志》评选出的展示全球人工智能最新发展的十大博客
[llm-examples](/Users/wwfyde/Projects/llm-examples)
- AI落地
- 任务规划引擎
- Agent 架构
- Task
- 聚类算法
**检索增强生成(RAG)**通过动态知识融合技术突破大模型的静态知识边界;
**智能体(Agent)**借助自主决策与多任务协同能力重构人机协作范式;
多模态大模型则依托跨模态语义理解技术解锁复杂场景的落地潜力。
**RAG:**大模型的动态知识引擎,解决模型静态知识边界、时效性与可信度问题。
**Agent:**大模型的智能执行中枢,赋予模型自主规划、决策与工具调用能力。
**多模态:**大模型的感知升级底座,突破单一模态理解限制,实现真实世界全息认知。
知识增强(RAG)→ 行为智能(Agent)→ 感知升级(多模态)→ 完整智能体
- playwright
- browser-use
- sglang
- vllm
- deepspeed
- ollama
- cherry studio
MCP HOST:
- 内容生成
- 自动化处理-Agent
意图识别(intent Classification) intent recognition
意图识别(Intent Classification),是一种自然语言处理技术,用于分析用户的输入并将其映射到某个预定义的意图类别。这种技术在问答机器人、智能客服、虚拟助手等领域被广泛使用。其目的是通过分析用户的文本或语音输入,识别用户的询问、请求或指示真正的目的,从而提供个性化、准确的服务。
task goal
AI agents, Agentic AI
- 微信::智东西::Agent综述论文火了,10大技术路径一文看尽
- 微信::TsingtaoAI::三大行业案例:AI大模型+Agent实践全景
- Anthropic::Blog::build-effective-agents
- OpenAI::Blog::a-practical-guide-to-building-agents
- lovart Design Agent
- Anthropic::article::Agents solutions
-
An agent is a system that uses a model to decide how to act in an environment in pursuit of a goal.
-
Ahthropic: "Agent" can be defined in several ways. Some customers define agents as fully autonomous systems that operate independently over extended periods, using various tools to accomplish complex tasks.
- Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
- Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
-
Agentic工作流: 为实现特定任务或目标而设计的一系列连接步骤
-
Agentic AI uses sophisticated reasoning and iterative planning to autonomously solve complex, multi-step problems.
-
RPA与Agent
-
Tool Use(function call):
-
Tool Use, in which an LLM is given functions it can request to call for gathering information, taking action, or manipulating data, is a key design pattern of AI agentic workflows. -- Andrew.N
- Agent的架构模块的划分略有差异,但基本上包含了:感知,记忆,规划,行动四个核心的要素。
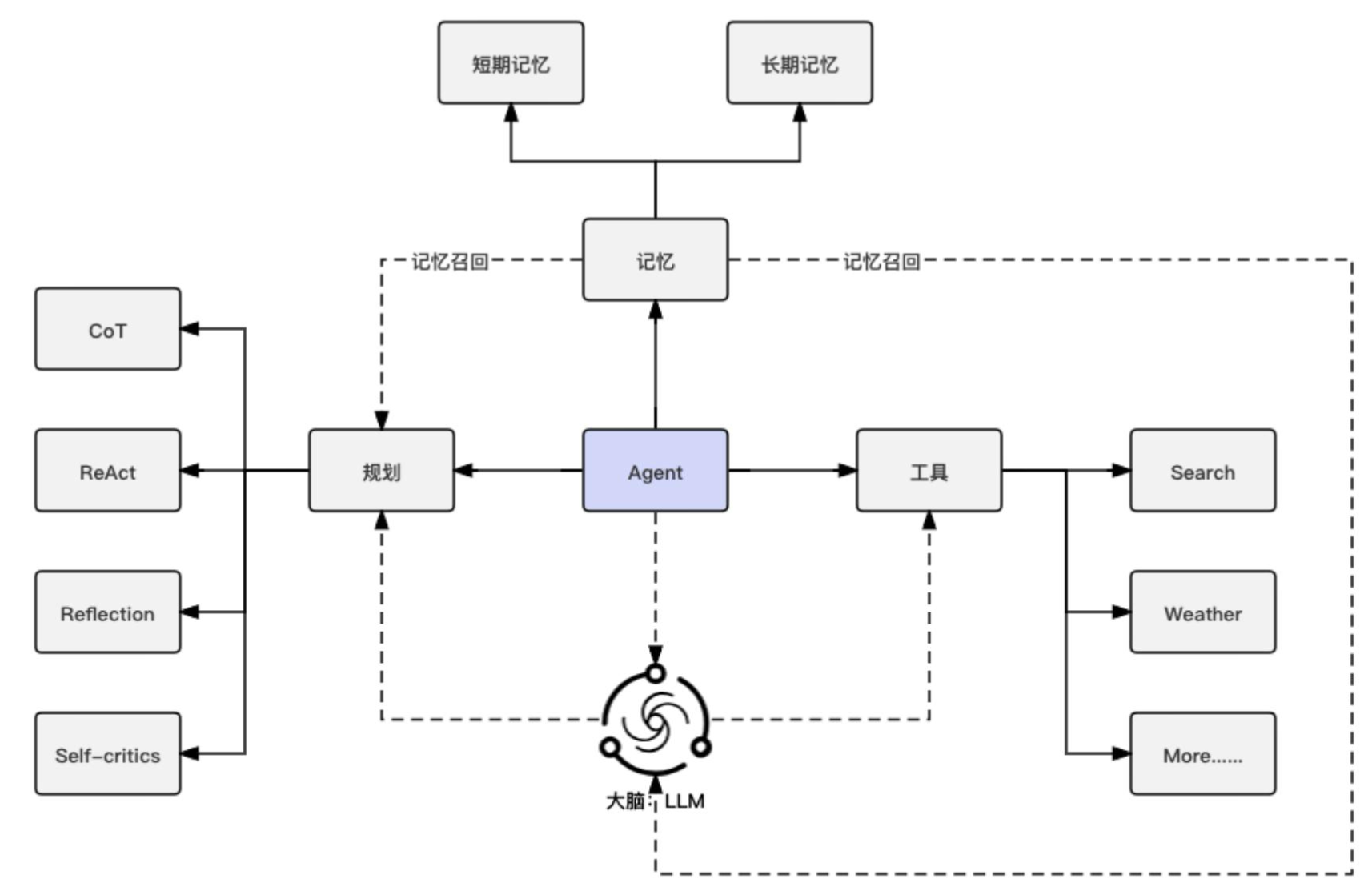
block
workflow
agent
gate
route
parallelization/
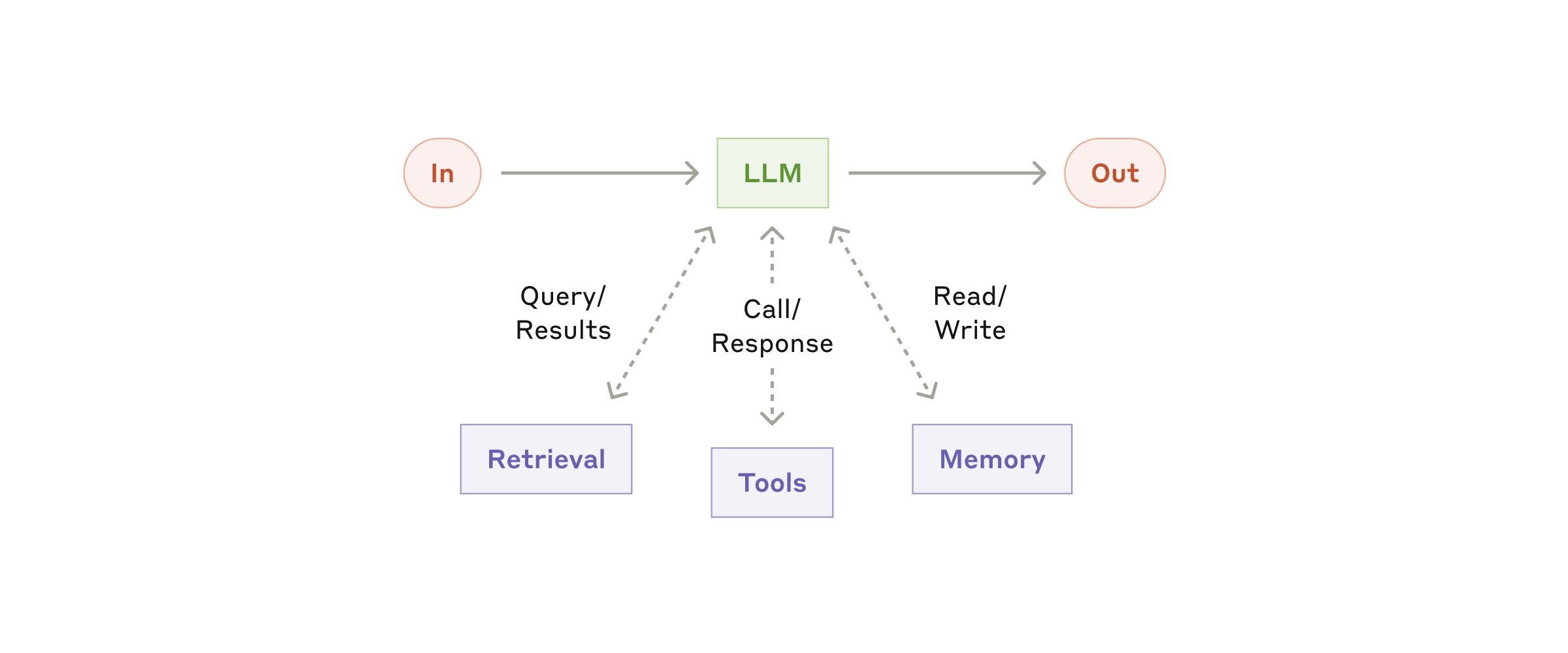
构建 块(blocks), 工作流(workflows), 智能体(agents) 基础构建块
块: The basic building block of agentic systems is an LLM enhanced with augmentations such as retrieval, tools, and memory. Our current models can actively use these capabilities—generating their own search queries, selecting appropriate tools, and determining what information to retain.
- f ->x = f(x) (预测下一个token)
- 改变f就是训练
- 改变参数f就是训练(training)或者学习(learning)
- 改输入x(训练人类): 切语言模型合适的输入, 让语言模型得到预期的输出结果
- prompt engineering 与context engineering 区别
- 关注点不一样
- 核心就是改变输入来使结果符合预期, 改善
- 指派任务, 指导模型, 约束条件, 输出格式
- in-context learning
| 模型 | 所属家族 | ||||||
|---|---|---|---|---|---|---|---|
| OpenAI | |||||||
| QWen | |||||||
| 代码 | 多模态 | ||
|---|---|---|---|
| Claude | ★☆ | ||
| OpenAI | |||
| Gemini |
- API结构化输出示例——Introducing Structured Outputs in the API
- OpenAI: 结构化输出Structured Outputs
- 语音转文本Whisper——(Speech to text)
Note
平台对API调用请求没有设置速率限制,但会受到模型官方的速率限制。
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
input="Your text string goes here",
model="text-embedding-3-small"
)
print(response.data[0].embedding)Typically, a conversation will start with a system message that tells the assistant how to behave, followed by alternating user and assistant messages, but you are not required to follow this format.
| 模型名称 | model id | 渠道商 | 基座模型 | 参数量 | input price | output price | cache price | 发布日期 | 网址 | 开源 | 发布者 | 备注 | 价格网址 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gpt-4o | $5 | $20 | $0.75 | ||||||||||
| gpt-4o-mini | $0.6 | $2.4 | |||||||||||
| gpt-4.1 | $5 | $12 | |||||||||||
| gpt-4.1-mini | $0.4 | $1.6 | |||||||||||
| gpt-4.1-nano | $0.1 | $0.4 | |||||||||||
| claude-sonnet-4 | $3 | $15 | |||||||||||
| claude-opus-4 | $15 | $75 | |||||||||||
| qwen-vl-32b-instruct | 通义 | 125K | ¥8 | $24 |
嵌入, 向量化, 向量表示, 特征
- ollama
- cherry studio
- vllm
- sglang
- 可靠性:99.9%的系统正常运行时间,遵循结构化输出标准
- 安全性:不产生冒犯性、不适宜工作场所或有害的内容
- 事实一致性:忠实于所提供的上下文,不虚构信息
- 实用性:满足用户的实际需求和请求
- 可扩展性:符合时延服务等级协议,能够支撑的吞吐量
- 成本:预算有限
- 其他:安全性、隐私性、公平性、GDPR合规性、DMA合规性等
https://github.com/lumina-ai-inc/chunkr
https://github.com/VikParuchuri/surya
Links https://www.databricks.com/glossary/retrieval-augmented-generation-rag
qdrant
millvus 索引
https://github.com/langflow-ai/langflow
https://x.com/akshay_pachaar/status/1783114329199718558
fastgpt, dify, ragflow, lamma_index
ragflow 意图识别开发
相关文档
更多参考 AI
- 神经网络(neural network):
- AWS 什么是神经网络
- YouTube 什么是神经网络
- 为何人脑能够将不一样的(3), 但相似的视觉信号识别为相同的东西, 但是有能区别不同的视觉信号, 模式识别
- 当程序中要对模式识别的信息(3)进行视觉表示时该如何处理
- 神经元更像是一个函数
- ReLU(线性整流函数)
- 神经元
- 节点(知识/材料/概念), 连接(联系):
- 生物学
- 人脑:神经网络可以比作人脑,其中节点代表神经元,连接代表突触连接。
- 神经元: 节点可以形象化为神经元,接收来自其他神经元的信号,并将其传递给下一个神经元
- 突触:连接可以形象化为突触,是神经元之间传递信号的桥梁。
- 计算类比:
- 函数:神经网络可以比作一个函数,将输入数据映射到输出数据。
- 节点:节点可以形象化为函数中的计算单元,执行加减乘除等运算。
- 连接:连接可以形象化为函数中的参数,控制计算过程。
- 形象标识
- 抽象表示: 节点是一个向量, 包含该的属性, 例如激活值(activation), 权重(weight)等; 连接是一个矩阵, 代表不同节点连接之间的连接权重; 层: 可以比作神经网络中的不同功能模块,例如输入层、隐藏层和输出层。
- 权重: 可以比作连接两个神经元的突触的强度,决定了信号传递的强度。
- 激活函数: 可以比作神经元的兴奋程度,决定了神经元是否会将信号传递给下一个神经元。
- 偏置(bias): 可以比作神经元的阈值,决定了神经元需要多少信号才会被激活. 偏置实际上是对神经元激活状态的控制。。
- 训练: 可以比作训练一个运动员,通过不断地练习和调整,提高神经网络的性能。
- 神经元: 可以比作一个生物细胞,接收来自其他神经元的信号,并将其传递给下一个神经元。
- 权重矩阵*向量偏置就
- Python(PyTorch)中的表示: 节点(nn.Module), 连接(nn.Parameter)
- 强化学习
- 卷积神经网络
- 递归神经网络
- 深度神经网络
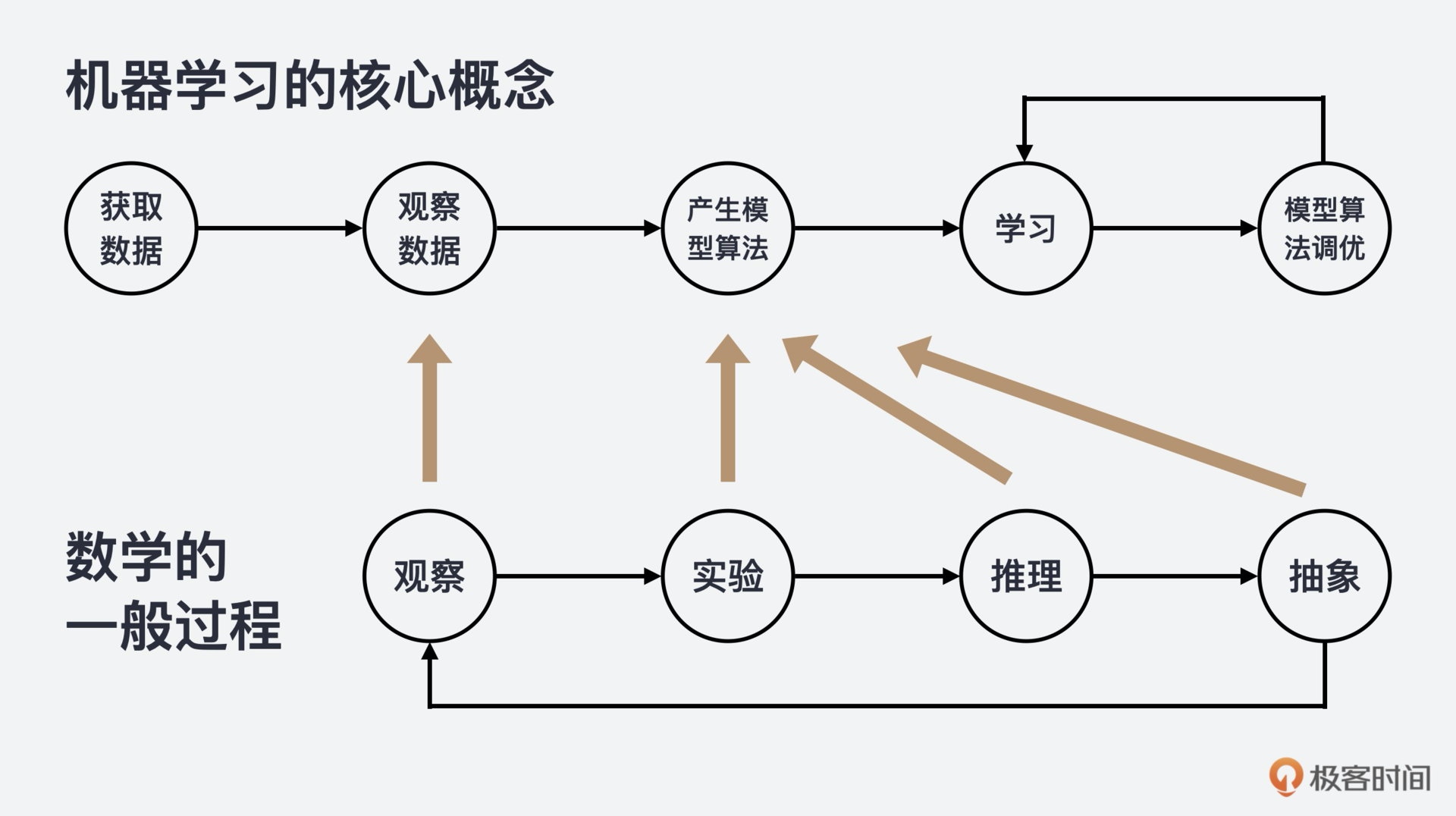
- 机器学习(Machine Learning):
- 机器学习的三个核心概念: 数据、模型和学习
- 模型(model)
- [Microsoft]机器学习模型是一个文件,在经过训练后可以识别特定类型的模式。 你可以用一组数据训练模型,为它提供一种算法,模型利用该算法学习这些数据并进行推理。
- 表示一个知识, 数据的结构
- 模型是一种简化. 它是对现实时间的解释——把与解决问题密切相关的方面抽象出来, 而忽略无关的细节.
- "数据"是学习的前提, 机器学习的第一步就是要进行数据的收集、预处理和特征提取; 而模型就是通过数据来学习算法; 学习则是一个循环过程, 一个自动在数据中寻找模式, 并不停调优模型参数逇过程. ——《极客时间·重学线性代数》
- 参数
- 算法
- 训练(Train)
- 推理(infer/reasoning)
- 评估(Evaluate)
- 预测(Predict)
- 分类(classification, classify)
- 提示(Prompt): 提示词
- 思维链(Chain-of-Thought, CoT)
- 思维树(Tree-of-Thoughts, ToT)
- 标量(scalar)
- 向量(vector)
- 矩阵(matrix)
- 卷积(convolution)
- transformer
- attention
- Lora
- VAE
- RAG(Retrieval-Augment Generation): 检索增强生成
- https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
- RAG is an AI framework for retrieving facts from an external knowledge base to ground large language models (LLMs) on the most accurate, up-to-date information and to give users insight into LLMs' generative process.——IBM: What is retrieval-augmented generation?
- fine-tuning(微调)
- ONNX
- KNN(K-Nearest Neighbor, 最近邻分类算法)
- 姿态控制(pose control)
- 姿态检查(pose detect)
- it/s(iterations per second, 每秒完成的迭代次数)
- 迭代是机器学习和深度学习过程中的一个重要概念,通常涉及到对数据集的单次完整处理或模型的一次更新步骤。
- 迭代过程:在训练或生成过程中,模型会逐步调整其参数以优化特定的任务(例如图像生成)。每一次的调整过程被称为一次迭代。
- 性能指标:it/s 表示每秒钟模型能够完成多少次这样的迭代。这个指标可以用来衡量模型运行的速度。较高的值通常表示模型处理速度快,可以更快地完成任务。
- 应用场景:在生成图像的过程中,每次迭代可能涉及到对图像的一次修改、调整或改进。迭代次数可能与最终图像的质量和生成速度有关。
- In-context learning(ICL, 上下文学习, 语境学习)
- 华为云知识-人工智能知识图谱: 知识图谱是一种用于组织和表示结构化知识的图形 数据库 模型,它将现实世界中的事物、概念、关系等信息以图形的形式进行建模,并使用图形数据库技术来存储和查询这些数据。
- 机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。(人工智能讲义)
- Most machine learning workflows involve working with data, creating models, optimizing model parameters, and saving the trained models. This tutorial introduces you to a complete ML workflow implemented in PyTorch, with links to learn more about each of these concepts.
- 大多数机器学习工作流程涉及到数据处理, 模型创建, 模型参数微调和预训练模型保存.
Tensors are a specialized data structure that are very similar to arrays and matrices. In PyTorch, we use tensors to encode the inputs and outputs of a model, as well as the model’s parameters.
Tensors are similar to NumPy’s ndarrays, except that tensors can run on GPUs or other hardware accelerators. In fact, tensors and NumPy arrays can often share the same underlying memory, eliminating the need to copy data (see Bridge with NumPy). Tensors are also optimized for automatic differentiation (we’ll see more about that later in the Autograd section). If you’re familiar with ndarrays, you’ll be right at home with the Tensor API. If not, follow along!
import torch import numpy as np
Tensors are a specialized data structure that are very similar to arrays and matrices. In PyTorch, we use tensors to encode the inputs and outputs of a model, as well as the model’s parameters.
马尔科夫模型, 马尔科夫链(Markov Chain)
-
语音识别
-
预测
-
AI备忘录
-
AI助教
- Tokens: basic units of text/code for LLM AI models to process/generate language.—— Token: LLM AI模型中文本或代码的基础单元, token用于处理/生成语言.
- 在大语言模型(LLM)中,"Token"指的是文本被分解成的基本单位,用于模型处理和理解。这些Token可能是单词、字符或子词片段。Token的数量是衡量模型训练数据规模的一个关键指标,影响模型的理解能力和生成能力。一个模型处理的Token足够多,意味着它被训练在更广泛的文本上,理论上能更好地理解语言的复杂性,提高在自然语言处理任务上的表现。
- 原提问: 大语言模型(LLM)中常常会提到多少Token 当中的Token含义是, 该指标有何种意义
- 模型可理解的最小基本单位
- Tokenization: splitting input/output texts into smaller units for LLM AI models.
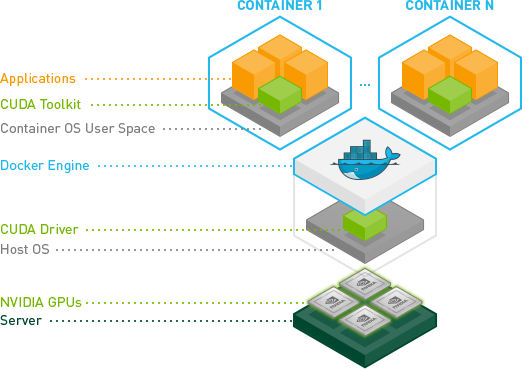
- CUDA (Compute Unified Device Architecture): CUDA是NVIDIA推出的一个并行计算平台和编程模型,它允许开发者利用NVIDIA的GPU进行通用计算。通过CUDA,开发者可以使用NVIDIA的GPU来加速科学计算、数据分析、金融建模等需要大量计算的任务。
- CUDNN(Compute Unified Device Architecture Deep Neural Network): CUDNN是NVIDIA提供的一套深度神经网络库,专门为深度学习应用程序优化。它提供了自动 Differentiation 和性能优化,使得开发者可以更容易、更快地在NVIDIA GPU上实现和训练深度学习模型。
- TensorRT: TensorRT是一个高性能深度学习推理(inference)引擎,它可以让开发者在不牺牲准确性的情况下,提高深度学习应用的推理速度。TensorRT通过优化深度学习模型,减少内存占用,并利用NVIDIA GPU和DPU进行高效推理。
- PyTorch: PyTorch是一个开源的机器学习库,广泛用于应用如计算机视觉和自然语言处理等领域的深度学习。PyTorch提供了灵活的动态计算图(称为张量),并支持CUDA,这使得在NVIDIA GPU上进行深度学习研究和开发变得非常方便。
- Conda: Conda是一个开源的包管理和环境管理系统,由Anaconda公司开发。Conda可以简化Python环境的配置和管理,支持多种编程语言的包,包括PyTorch、TensorFlow等深度学习框架。
- NVIDIA GPU: 即图形处理单元,NVIDIA公司生产的高性能处理器,广泛用于图形渲染、游戏和深度学习等。
- NVIDIA DPU (Data Processing Unit): 数据处理单元,是NVIDIA推出的新型计算架构,专注于数据处理和高性能计算。
- cuDNN: 这是CUDA Deep Neural Network的缩写,是用于深度学习应用的CUDA库的子集,专门针对深度神经网络进行优化。
Note
CNN 主要用于图像处理和计算机视觉任务。
RNN 和 Transformer 适用于序列数据和自然语言处理。
GAN 主要用于生成任务。
GNN 适用于图结构数据。
自编码器常用于降维和特征学习。
强化学习架构用于决策和控制问题。
()
如果需要安装cuda可以直接通过cuda安装Nvidia Driver
Important
推荐通过cuda toolkit 安装
# 安装必要构建依赖
sudo apt-get update
sudo apt-get install build-essential pkg-config dkms
# 注意gcc版本,
#
# Add CUDA to PATH
# CUDA PATH
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:${LD_LIBRARY_PATH}}CUDA Deep Neural Network library(CuDNN)是由NVIDIA开发的一个开源库,专门为深度学习应用程序设计,以提高GPU加速的效率。CuDNN提供了经过优化的数学运算,例如卷积、池化和归一化,这些运算对于训练和推理深度神经网络至关重要。它紧密集成了CUDA Toolkit和NVIDIA驱动程序,利用了GPU的并行处理能力,从而显著提高了深度学习任务的性能。
CuDNN广泛应用于深度学习领域,包括: 图像识别和分类 物体检测和分割 自然语言处理 强化学习 计算机视觉研究
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
# 生效
~/miniconda3/bin/conda init
~/miniconda3/bin/conda init zsh
# 取消激活(可选)conda config --set auto_activate_base false
conda config --add channels conda-forge # 添加社区版频道(推荐)
conda config --show
conda config --show-sources# no package install
conda create -n env-name python=3.x
# default packages
conda create -n env-name
# 查看虚拟环境中的package list
conda list
# 激活虚拟环境
source /path/to/conda/etc/profile.d/conda.sh
source ~/miniconda/etc/profile.d/conda.sh
source ~/anaconda/etc/profile.d/conda.sh
conda activate
# conda 的虚拟环境如果要使用pip(不推荐)
# https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html#using-pip-in-an-environment
conda install -n myenv pip
conda activate myenv
pip <pip_subcommand>
# 导出已安装包
conda env export > environment.yml
# 移除某个包
conda remove
conda remove -n myenv --all
# 从environment.yml文件中创建虚拟环境
conda env create -f environment.yml
conda remove -n myenv --all
# 移除某个环境
conda env remove -n gan
conda env remove --name gan
source "$HOME/miniconda3/etc/profile.d/conda.sh"
conda activate comfyuiauto_activate_base: bool这是正确的, 这和venv等方式创建的虚拟环境不同, conda是默认不会安装pip/python的,因为conda有自己的包管理和环境管理方式: conda list|create|install. 一般不建议pip和conda同时使用, 可能会发生冲突 参见: Using pip in an environment .
如果需要通过conda创建pip/python虚拟环境有两种方法可以做到
# 方法一 创建环境时指定python版本
conda create -n env python=3.12 # 该方法下conda会默认安装pip和python到env目录中
# 方法二 通过conda安装pip
conda create -n env
conda install pip
# 方法三 通过配置文件.condarc中的create_default_packages变量source /path/to/conda/etc/profile.d/conda.sh
conda activate- 构建快(building blocks)
- Tensor
- Autograd Module
- Neural Network Module
- Optimizers
- Data Loading and Processing
- UDA Support for GPU Computing:
# 创建模型, 也是一个神经网络节点
torch.nn.Module
# 利用多个GPU
CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两links:
docker pull nvidia/cuda:12.6.1-cudnn-devel-ubuntu24.04
# 推荐
docker pull nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04
docker run --gpus all --name comfyui -it nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04
# 使用其中一个GPU
nvidia-smi -L # 查看ID和uuidz
docker run --gpus all --rm -it nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 /bin/bash
docker run --gpus device=0 --rm -it nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 /bin/bash
docker run --gpus 2 --rm -it nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 /bin/bash # 指定数量
docker run --gpus '"device=0,1"' --rm -it nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 /bin/bash 将远程端口映射到本地端口 以实现连接访问
# Safari 浏览器中支持SF Mono
ui-monospace, 'SF Mono'jupyter notebook --no-browser --port=8888 --ip=0.0.0.0
jupyter notebook password
- 费曼学习法, 中英文提问和回答
-
nvcr.io/nvidia
使用ossfs将OSS Bucket挂载到Linux系统的本地目录
docker login nvcr.io
sudo apt-get install -y docker nvidia-container-toolkit构建包含特定环境的容器
- g4dn
- ssh 登录
- sudo apt-get update
- sudo apt-get install build-essential
- 安装cuda (包含驱动, 也可先安装驱动)
- 安装**
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
docker run --rm --runtime=nvidia --gpus all nvidia/cuda:12.3.1-runtime-ubuntu22.04 nvidia-smi
docker run -it --rm --gpus all nvcr.io/nvidia/pytorch:23.12-py3 /bin/bash
# 机器学习容器pytorch
# https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch
FROM nvcr.io/nvidia/pytorch:23.12-py3 as baseFROM nvcr.io/nvidia/pytorch:23.12-py3 as base
ENV TZ=Asia/Shanghai分布式存储解决方案
参考 Linux
- https://paperswithcode.com/task/semantic-segmentation
- https://segment-anything.com/
- https://github.com/xenova/transformers.js
- 演示地址之一
一句话, 摘要, 全文
remind.ai
学科辅导, 课程辅导
- Bard
- GPT4
- Claude
- DeepL
Design pattern
reflection-反思
- Self-Refine: Iterative Refinement with Self-Feedback, Madaan et al. (2023)
- Reflexion: Language Agents with Verbal Reinforcement Learning, Shinn et al., (2023)
tool use-使用工具
GMIRACT: Proming Mail Tor emit Mason and Alita, Yang et al. (2023)
planning -规划
Hugging i: Soring A Task wit ason and as Fiend an Hugging - We, stal, a, 2023)
multiagent collaboration-多智能体协作
-
Asking general questions about software development in natural languages
-
Generating code
-
Generating code comments or code documentation
-
Explaining bugs and offering fixes for them
-
Explaining the code
-
Generating tests
-
Search in natural language queries for code fragments
-
Performing code review
-
Summarizing recent code changes to understand what happened more quickly
-
Refactoring code
-
Generating CLI commands by natural language description
-
Generating commit messages
约会话题-智谱AI
chatflow
用户意图(intention)识别
使用 transformer.js 库 v2.14

控制中心
- 注入参数约束
- 使用graph
- 使用动态提示词, 通过context 注入
- 使用state_schema
- 一个用户可以有多个会话,而 一个会话每个会话开启一个agent
- checkpointer: 短期记忆, 创建一个agent 多次调用, 用于维持会话状态
- store: 长期记忆, 整个用户都有效
- 重新create_agent 后 AgentState 会丢失, 所以一个会话重新创建一个AgentState
- langchain 通过 thread_id 来隔离短期记忆
- 核心对象
- user_id
- session_id
- conversation_id(thread_id)
- profile_id
- 流程控制, 比如并行时的执行,
- 如何持久化状态
- 流程控制, 是
- 定义条件边, 通过还是来确定 builder.add_conditional_edges('a', func)
- 条件边函数()
- 通过Command来控制边, 在节点来判断返回next_node
- 边(Edge)定义控制流, 但他们并不控制Node可以访问的数据
所有节点共享State
Serial(串行), parallel
conditional
human in the loop
LLM Agents
- Claude: 无框架高效构建Agent
- Claude Agent Solutions
- AWS Bedrock Agents
- What Are Agentic Workflows?
- Camel Agent
- owl
- 如何评价当前的 AI Agent 落地效果普遍不佳的问题?
- 公众号::智东西::Agent综述论文火了,10大技术路径一文看尽
- Bilibili::沧海九粟::12要素智能体
- Bilibili::沧海九粟::什么是Agentic工作
- a workflow is a series of connected steps designed to achieve a specific task or goal.
Github::FoundationAgents::OpenManus
- 构建Agent的目标是解决特定问题
- Tool Use, in which an LLM is given functions it can request to call for gathering information, taking action, or manipulating data, is a key design pattern of AI agentic workflows. --Andrew.Ng
- prompt as function(提示即函数)
- 构建AI应用的三大核心要素:模型、数据和智能体
- google::vertex: 您可以使用 Vertex AI 来编排生产 AI 的三大核心要素:模型、数据和智能体。
- LightRAG
- StructRAG
- GraphRAG
- agno
-
构建Agent的多种模式
- 无框架模式
- openai, qwen,
- 框架
- UI-TARS
- agno
- 无框架模式
-
models
- doubao, qwen, openai
-
UI
- ag-ui
- copilotkit
-
Agent模式
-
ReAct
- thought -> action -> observation
- 思考 -> 行动 -> 观察
-
function call
-
MCP
-
A2A
-
意图-intent
实体-entity
架构模式 以及交互策略
- 统一对话接口:AutoGen的每个agent都可以接收、反应和响应消息,实现了统一的消息传递机制。这种设计利用了最先进的LLM在通过聊天进行反馈和推进的能力。
- 工具集成
- 人类代理参与
- 多角色/多agent
- 维护对话状态, memory
- 通过context指定上下文信息
- 通过State来实现multi-agent协作
https://github.com/langchain-ai/langgraph-supervisor-py
AgentState
该模式已被弃用
- langgraph swarm
agents dynamically hand off control to one another based on their specializations. The system remembers which agent was last active, ensuring that on subsequent interactions, the conversation resumes with that agent.
常见问题
- 如何触发工具调用:
- Prompt显式引导, call tool create_image
- LLM判断, 需要注意tool name 和 description
https://googleapis.github.io/python-genai/
| 111111111111 | 222222222222222 | 44444444444444 | eeeeeeeeeeeeeeeeeeeeeeeeeeeee | ererrrr | 44444444444 | |
|---|---|---|---|---|---|---|
- function call 不支持 文件作为输入, 只能使用 url string, base64 string, 这是有json schema 限制的
多模态API图片Tokens用量完全指南:预估成本与优化策略
在调用多模态API时,有两种主要方式提供图像:通过Base64编码或URL链接。这两种方式各有优缺点,下面通过表格详细对比:
| 特性 | Base64编码 | URL链接 |
|---|---|---|
| Token消耗 | 较高(额外消耗约30%) | 较低(仅URL字符本身) |
| 处理速度 | 较快(无需额外网络请求) | 较慢(需AI服务器下载图片) |
| 稳定性 | 高(不依赖外部资源) | 中(依赖图片服务器可用性) |
| 适用场景 | 本地图片、对延迟敏感场景 | 已上传至公网的图片、对成本敏感场景 |
| 实现复杂度 | 中(需要编码处理) | 低(直接提供链接) |
| 安全性 | 高(直接传输内容) | 中(需保证链接安全可访问) |
| 大小限制 | 更容易达到API请求大小限制 | 较少受API请求大小限制 |
重要结论: URL方式确实消耗较少的输入tokens(通常只有URL字符串本身的tokens),但处理效率可能较低,因为AI服务需要先下载图片。如果应用对延迟敏感,Base64可能是更好的选择;如果对成本更敏感,URL方式更合适。