| name | 并发编程 |
|---|
并发 与异步概念 理解 异步时 之在非阻塞的情况下实现多任务
并发 解决多任务的问题(单线程 阻塞)
异步 则解决阻塞的问题 (单线程 非阻塞)
异步与同步是一对概念,在方法调用的时候,如果我们等待方法调用的返回则是同步,不等待而继续执行程序流则是异步。从处理器的角度来看,有些操作消耗的时间,远远高于其运行指令的时间,比如从网络获取数据,写入文件到磁盘等。如果采用同步方式,则大大的浪费了处理器的计算能力。在IO密集型的应用里,异步调用成为提高软件性能的关键方法。
T
- 异步通俗讲就是可以挂起后重新执行, 这样的过程通常对执行顺序不敏感
- 通过异步特性可以获得并发执行代码的能力, 因为异步可以挂起代码并让出控制流(control flow)
- 可以将代码封装为任务(task)或作业(job)的情形, 允许并发处理concurrent processes;
一个时间段内CPU同时运行多个程序, 通过时间片轮转来实现在一个时间周期内运行多个程序, 给人的感觉是多个程序在同时运行, 而不必等
现并发执行的方式多样,涵盖了从底层的硬件支持到高层的软件设计模式与架构。并发编程旨在允许多个任务在同一时间段内执行,以提高资源利用率和应用性能。以下是实现并发执行的几种主要方式,包括底层的编程技术、并发模型、设计模式和软件架构。
硬件层
n个CPU同时运行n程序,
在计算机科学中,同步是协调多个进程在某一点上联合或握手的任务,以达成协议或承诺一定的行动序列。In computer science, synchronization is the task of coordinating multiple of processes to join up or handshake at a certain point, in order to reach an agreement or commit to a certain sequence of action.
- 涉及到任务处理时, 任务必须串行(按顺序)执行, 尤其是涉及到并发模型中,
谈到同步与异步时, 语境就是IO操作和阻塞问题
(网络/文件)I/O操作时, 必须等待IO操作完成才返回的调用方式; 这种情形下会阻塞线程, 无法继续执行后续代码, 必须等IO完成了
在并发编程语境中, 同步是指任务之间只能顺序执行, 下一个任务执行的前提是
I/O操作, 并发编程中, 程序是否会挂起可后台执行
这是函数调用中的概念
- 对于IO操作来说, 多线程和多进程性能差别不大
- 线程是一个轻量级的调度对象
- 主线程结束时,主进程不一定退出
操作系统可以同时运行多个任务
任务切换 一般指的是进程切换 (因为涉及到资源分配问题)
什么叫“多任务”呢?简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。 表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。 真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
并发:指的是任务数多余cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已) 并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的
理解主线程和子线程的关系
使用threading.Thread类能够创建线程对象
threading.Thread 的 target 参数能够指定线程执行的任务
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。 一个标准的线程由 线程ID , 当前指令指针(PC) , 寄存器集合 和 堆栈 组成
另外,线程是进程中的一个实体,是被系统调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。
线程(thread):是操作系统能够进行运算调度的最小单位 它被包含在进程之中,是 进程 中的实际运作 单位。 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
当一个程序启动时,就有一个进程被操作系统(OS)创建, 与此同时一个线程也立刻运行, 该线程通常叫做程序的主线程
主线程的重要性有两个方面:
1. 是产生其他子线程的线程
2. 通常他必须最后完成执行比如执行各种关闭动作.
可以看做是程序执行的一条分支,当子线程启动后会和主线程一起同时执行
python的thread模块是比较底层的模块,python的threading模块是对thread做了一些包装的,可以更加方便的被使用
使用threading模块
# coding=utf-8
import threading
import time
def say_sorry():
print("亲爱的,我错了,我能吃饭了吗?")
time.sleep(2)
if __name__ == "__main__":
for i in range(5):
t = threading.Thread(target=say_sorry) # 创建子线程
t.start() # 启动线程,即让线程开始执行instructions 可以明显看出使用了多线程并发的操作,花费时间要短很多 当调用start()时,才会真正的创建线程,并且开始执行
查看正在活动的线程的数量
threading.enumerate()函数 能够获取当前所有活跃线程的列表
len(list) 可求出列表的长度, 从而实现查看当前活跃的线程的个数
获取当前线程对象 (含名称)
向线程函数传递多个参数
能够说出多线程执行的顺序特点
args 参数
kwargs 参数
import threading
import time
def sing(a, b, c):
print('---sing---: ',a, b, c)
for i in range(5):
print(i + 1, ' ', '正在唱歌...')
time.sleep(0.5)
# 带值参数用法: kwargs = {'name': 'wwfyde', 'age': 24}
t1 = threading.Thread(target=sing,args=(10,22,100))
t1.start()
# sing(1,2,3)使用setDaemon设置子线程守护主线程
默认主线程退出了子线程不会结束
守护线程: 如果在程序中将子线程设置为守护线程, 则该子线程将会在主线程结束时自动退出, 设置方式为thread.setDaemon(True), 要在thread.start()之前设置, 默认是False, 也就是 默认线程 主线程结束时,子线程依然在执行.
import threading
import time
def work1():
for i in range(10):
print('正在执行...', i)
time.sleep(0.5)
if __name__ == '__main__':
t1 = threading.Thread(target=work1)
t1.setDaemon(True)
t1.start()
time.sleep(2)
print('Game Over! ')
exit()并行和并发的区别
多任务的实质是操作系统轮流让各个任务交替执行 由于CPU执行速度实在是太快了, 我们感觉就像所有任务都在同时执行一样.
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多 于CPU的核心数量, 所以,操作系统也会自动把很多任务轮流调度到每个核心上执行
时间片轮转, 优先级调度
==测试==
并发: 任务数多余CPU核数, 通过操作系统的各种任务调度算法, 实现多个任务 '一起' 执行(实际上总有一些任务不在执行,因为切换任务的速度相当快, 看上一起执行而已)
并行: 指的是任务数小于等于CPU核数, 既任务真的是一起执行
-
主线程会等所有的子线程结束后才结束
-
主线程和子线程之间是按照顺序并且同时执行的
-
但是,线程之间的执行顺序是随机的
- 线程的运行顺序是随机的
- 通过延时的方式可以搞定执行顺序,
-
主线程和子线程之间不会相互影响
-
程序结束才意味着主线程结束
-
子线程执行完毕后会自动结束
-
子线程的开始是从调用start()时开始的
-
模拟多人同时执行任务
-
线程间会有一种循环
通过使用threading模块能完成多任务的程序开发,为了让每个线程的封装性更完美,所以使用threading模块时,往往会定义一个新的子类class,只要继承threading.Thread就可以了,然后重写run方法
python的threading.Thread类有一个run方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法。而创建自己的线程实例后,通过Thread类的start方法,可以启动该线程,交给python虚拟机进行调度,当该线程获得执行的机会时,就会调用run方法执行线程。
#coding=utf-8
import threading
import time
class MyThread(threading.Thread): # 继承父类,并重写run方法
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm "+self.name+' @ '+str(i) #name属性中保存的是当前线程的名字
print(msg)
if __name__ == '__main__':
t = MyThread()
t.start()线程的执行顺序是不确定的. 当执行到sleep语句时, 线程将被阻塞(Blocked), 到sleep结束后, 线程进入就绪状态(runnable),等待调度. 而线程调度将自行选择一个线程执行(由操作系统决定)
每个线程都运行完整个run函数,但是线程的启动顺序、run函数中每次循环的执行顺序都不能确定。
- 每个线程默认有一个名字,由线程对象自动生成,并制定一个名字.
- 当线程的run()方法结束时,该线程完成.
- 无法控制线程调度顺序,但可以通过别的方式来影响线程调度的方式.
CPU高并发执行原理
- 快速切换,循环执行 切换速度足够快就能呈现出同时执行的效果 伪多任务 时间片轮转 操作系统来决定的,调度时间 优先级操作
通过继承threading.Thread 实现自定义线程
重写线程类
通过使用threading模块能完成多任务的程序开发, 为了让每个线程的封装性更完美, 所以使用threading模块时, 往往会定义一个新的子类class, 只要
让自定义类 继承自 threading.Thread
让自定义类 重写 run() 方法
通过实例化自定义类对象.start()方法启动自定义线程
import threading
import time
class MyThread(threading.Thread):
def __init__(self, num):
# 调用父类的init方法
super(MyThread, self).__init__()
self.num = num
def run(self):
for i in range(5):
print('正在执行run方法...',self.name)
time.sleep(0.5)
def test(self):
pass
if __name__ == '__main__':
# 类的实例化 创建线程对象
mythread = MyThread(10)
mythread1 = MyThread(10)
mythread.start()
time.sleep(0.1)
mythread1.start()说明:
-
python的threading.Thread 类有一个run方法, 用于定义线程的功能函数,可以再自己的线程类中覆盖该方法. 而创建自己的线程实例后, 通过Thread.start方法,可以启动该线程, 交给python虚拟机进行调度, 当该线程获得执行的机会时, 就会调用run方法执行线程
-
在 run方法中 使用self.name 可以获得当前正在运行的 线程名称
-
自定义线程执行原理
start()是子类继承父类得到的 调用start()方法, 但是对象的run方法被执行了, 说明start()方法中调用了 run方法
子类继承父类的 name 属性 (保存的是线程的名称)
不用传递参数 直接将执行代码写入run方法中
多线程会共享全局变量(相同的资源包)
- 在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据
- 缺点就是,线程是对全局变量更改可能造成多线程之间对全局变量的混乱(即线程非安全)
import threading
import time
num = 0
def work1():
global num
for i in range(10):
num += 1
print('work1 num = ', num)
def work2():
print('work2 num = ', num)
if __name__ == '__main__':
t1 = threading.Thread(target=work1)
t2 = threading.Thread(target=work2)
t2.start()
# 进程切换间隔
time.sleep(2)
t1.start()
# 只要子线程还未结束, 就让主线程一直进入阻塞状态
while len(threading.enumerate()) != 1:
time.sleep(1)
print('num = ', num)多线程共享全局变量数据会导致资源竞争问题
- 如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
但是由于是多线程同时操作,有可能出现下面情况:
- 在g_num=0时,t1取得g_num=0。此时系统把t1调度为”sleeping”状态,把t2转换为”running”状态,t2也获得g_num=0
- 然后t2对得到的值进行加1并赋给g_num,使得g_num=1
- 然后系统又把t2调度为”sleeping”,把t1转为”running”。线程t1又把它之前得到的0加1后赋值给g_num。
- 这样导致虽然t1和t2都对g_num加1,但结果仍然是g_num=1
问题分析(不断的 引用 处理 赋值) 因为 赋值和 引用没有顺序关系 就会出现问题
如果同时对全局变量进行赋值 就会出现 只加了一次的情况
这就是资源竞争问题, 为了解决这种问题 应该让(应用 - 处理 - 赋值) 这个子程序进行隔离 在执行时 不应该被允许其他线程修改 让原现场执行完了再进行修改
import threading
import time
num = 0
def work1():
global num
for i in range(1000000):
num += 1
print('work1 num = ', num)
def work2():
global num
for i in range(1000000):
num += 1
print('work2 num = ', num)
if __name__ == '__main__':
t1 = threading.Thread(target=work1)
t2 = threading.Thread(target=work2)
t2.start()
# 进程切换间隔
# time.sleep(1)
t1.start()
# 只要子线程还未结束, 就让主线程一直进入阻塞状态
time.sleep(0.01)
while len(threading.enumerate()) != 1:
time.sleep(1)
print('num = ', num)同步就是协同步调,按预定的先后次序进行运行。如: 你说完,我再说。
"同"字从字面上容易理解为一起动作
其实不是,"同"字应是指协同、协助、互相配合。
如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B执行,再将结果给A;A再继续操作。
sync async
同步: 多任务, 多个任务之间执行的时候要求有先后顺序, 必须一个先执行完成之后, 另一个才能继续执行, 只有一个主线(逻辑执行者为1). (同一时间只能做一件事情)
异步: 多个任务之间执行没有先后顺序, 可以同时运行, 执行的先后顺序不会有什么影响, 存在多条运行主线(逻辑执行者为多), 逻辑执行者之间互不影响.
(线程的封装是进程, 进程间不通信,就不会相互干涉)
可以通过线程同步来进行解决, 同一时间只能运行一个线程
思路,如下:
- 系统调用t1,然后获取到g_num的值为0,此时上一把锁,即不允许其他线程操作g_num
- t1对g_num的值进行+1
- t1解锁,此时g_num的值为1,其他的线程就可以使用g_num了,而且是g_num的值不是0而是1
- 同理其他线程在对g_num进行修改时,都要先上锁,处理完后再解锁,在上锁的整个过程中不允许其他线程访问,就保证了数据的正确性
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
互斥锁(英语:Mutual exclusion,缩写 Mutex)是一种用于多线程编程中,防止两条线程同时对同一公共资源(比如全局变量)进行读写的机制。该目的通过将代码切片成一个一个的临界区域(critical section)达成。临界区域指的是一块对公共资源进行访问的代码,并非一种机制或是算法。一个程序、进程、线程可以拥有多个临界区域,但是并不一定会应用互斥锁。
threading模块中定义了Lock类,可以方便的处理锁定:
import threading
# 创建锁
mutex = threading.Lock()
# 锁定
mutex.acquire()
# 释放
mutex.release()- 如果这个锁之前是没有上锁的,那么acquire不会堵塞
- 如果在调用acquire对这个锁上锁之前 它已经被 其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止
import threading
import time
g_num = 0
def test1(num):
global g_num
for i in range(num):
mutex.acquire() # 上锁
g_num += 1
mutex.release() # 解锁
print("---test1---g_num=%d"%g_num)
def test2(num):
global g_num
for i in range(num):
mutex.acquire() # 上锁
g_num += 1
mutex.release() # 解锁
print("---test2---g_num=%d"%g_num)
# 创建一个互斥锁
# 默认是未上锁的状态
mutex = threading.Lock()
# 创建2个线程,让他们各自对g_num加1000000次
p1 = threading.Thread(target=test1, args=(1000000,))
p1.start()
p2 = threading.Thread(target=test2, args=(1000000,))
p2.start()
# 等待计算完成
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2个线程对同一个全局变量操作之后的最终结果是:%s" % g_num)现实社会中,男女双方都在等待对方先道歉
如果双方都这样固执的等待对方先开口,弄不好,就分手了
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源释放(同步),就会造成死锁。
阻塞: 等待响应 等待返回结果(等待某个条件触发) 返回结果正确即执行
为什么会阻塞: 本线程挂起 只会执行本线程代码
指针指令一直在切换 只是 一直在死循环 因为双方都在等待返回值, 而因为指针无法运行对方的程序
-
被抢先上锁的原因是共享资源导致的资源竞争(程序代码块意外接受返回值)
-
阻塞的原因: 无法被再次唤醒,均处于阻塞状态(等待返回值,无法主动执行)
-
建立了两个临界区块, 对方线程无法访问该资源, 自身资源却没办法停止
-
虽然指令指针一直在切换,但因为判定问题(两个锁,处于阻塞状态(阻塞对方代码),自身线程拿不到值, 线程无法继续执行)而无法再继续读取代码
-
在同步的程序设计中,临界区块(Critical section)指的是一个访问共享资源(例如:共享设备或是共享存储器)的程序片段,而这些共享资源有无法同时被多个线程访问的特性。
-
临界区块(Critical section)指的是一个访问共享资源(例如:共享设备或是共享存储器)的程序片段,而这些共享资源有无法同时被多个线程访问的特性。 当有线程进入临界区块时,其他线程或是协程必须等待(例如:bounded waiting 等待法),有一些同步的机制必须在临界区块的进入点与离开点实现,以确保这些共享资源是被异或的使用,例如:semaphore。
-
死锁(英语:Deadlock),又译为死结,计算机科学名词。当两个以上的运算单元,双方都在等待对方停止运行,以获取系统资源,但是没有一方提前退出时,就称为死锁。在多任务操作系统中,操作系统为了协调不同行程,能否获取系统资源时,为了让系统运作,必须要解决这个问题。
当有线程进入临界区块时,其他线程或是行程必须等待(例如:bounded waiting 等待法),有一些同步的机制必须在临界区块的进入点与离开点实现,以确保这些共享资源是被异或的使用,例如:semaphore。
只能被单一线程访问的设备,例如:打印机。
一个最简单的实现方法就是当线程(Thread)进入临界区块时,禁止改变处理器;在uni-processor系统上,可以用“禁止中断(CLI)”来完成,避免发生系统调用(System Call)导致的上下文交换(Context switching);当离开临界区块时,处理器回复原先的状态。
线程上下文中, 需要条件为真的才会执行, 为0时表示阻塞, 当都阻塞时就没办法唤醒
#coding=utf-8
import threading
import time
class MyThread1(threading.Thread):
def run(self):
# 对mutexA上锁
mutexA.acquire()
# mutexA上锁后,延时1秒,等待另外那个线程 把mutexB上锁
print(self.name+'----do1---up----')
time.sleep(1)
# 此时会堵塞,因为这个mutexB已经被另外的线程抢先上锁了
mutexB.acquire()
print(self.name+'----do1---down----')
mutexB.release()
# 对mutexA解锁
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
# 对mutexB上锁
mutexB.acquire()
# mutexB上锁后,延时1秒,等待另外那个线程 把mutexA上锁
print(self.name+'----do2---up----')
time.sleep(1)
# 此时会堵塞,因为这个mutexA已经被另外的线程抢先上锁了
mutexA.acquire()
print(self.name+'----do2---down----')
mutexA.release()
# 对mutexB解锁
mutexB.release()
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == '__main__':
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()程序(program):例如xxx.py这是程序,是一个静态的
进程(process):是操作系统分配资源的基本单元
一个程序运行起来后,代码+用到的资源 称之为进程,它不仅可以通过线程完成多任务,进程也是可以的
线程(thread): 是操作系统能够进行运算调度的最小单位
一个进程包含了多个线程
- 就绪态:运行的条件都已经满足,正在等在cpu执行
- 执行态:cpu正在执行其功能
- 等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情
2个while循环一起执行
# -*- coding:utf-8 -*-
from multiprocessing import Process
import time
def run_proc():
"""子进程要执行的代码"""
while True:
print("----2----")
time.sleep(1)
if __name__=='__main__':
p = Process(target=run_proc)
p.start()
while True:
print("----1----")
time.sleep(1)- 创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
# -*- coding:utf-8 -*-
import os
from multiprocessing import Process
def run_proc():
"""子进程要执行的代码"""
print('子进程运行中,pid=%d...' % os.getpid()) # os.getpid获取当前进程的进程号
print('子进程将要结束...')
if __name__ == '__main__':
print('父进程pid: %d' % os.getpid()) # os.getpid获取当前进程的进程号
p = Process(target=run_proc)
p.start()Process([group [, target [, name [, args [, kwargs]]]]])
- target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码
- args:给target指定的函数传递的参数,以元组的方式传递
- kwargs:给target指定的函数传递命名参数
- name:给进程设定一个名字,可以不设定
group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法:
-
start():启动子进程实例(创建子进程)
-
is_alive():判断进程子进程是否还在活着
-
join([timeout]):等待该进程结束, (阻塞其他进程到当前进程结束,默认阻塞到进程结束,或者阻塞timeout=1.5 秒或到程序结束)
-
terminate():不管任务是否完成,立即终止子进程
join terminate 方法的使用
# 控制进程的执行时间 提前终止改程序
import multiprocessing
import time
def work1():
'''子进程的执行程序'''
print(time.ctime(),'只是子进程执行开始的时间')
print('开始执行')
time.sleep(2)
print('执行了2秒')
print(time.ctime(),'?')
time.sleep(2)
print('执行了4秒')
time.sleep(1)
print('执行了5秒')
print('执行完毕')
if __name__ == '__main__':
print(time.ctime(),'只是主进程执行开始的时间')
p = multiprocessing.Process(target=work1, name='test')
p.start()
# 等待子进程执行接收
p.join()
# 阻塞 主进程
# time.sleep(3)
print('主进程继续执行')
print(p.name)
print(time.ctime())
# p.terminate()Process创建的实例对象的常用属性:
- name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
- pid:当前进程的pid(进程号)
当前进程对象的获取:
multiprocessing.curr ent_process()
进程pid:
有两种方法可以获取
multiprocessing.current_process().pid
使用 import os 模块的getpid()
获取父id
os.getppid() 获取父进程id
kill -9 杀掉进程 (通过终端命令的方式这是)
kill -9 进程编号可以强制结束某个线程
import os
from multiprocessing import Process, current_process
import time
nums = [11,22]
def work1():
print('子进程对象的返回值:', current_process())
print('这是子进程的pid: ',current_process().pid)
print('这是子进程的name: ', current_process().name)
# 这只是类属性对象
# Process.join()
print('这是子进程1的运行状态',time.ctime())
print('如果后续代码代码未打印则表示该进程被提前终止了')
time.sleep(2)
# print(type(Process.name))
print("子进程执行了2秒")
def work2():
'''通过os 模块 获取进程的pid 和pid'''
# print('in 进程2 %s pid = %d , nums = %s' % (Process.name, os.getpid(), nums))
print('当前子进程2名称: ', os.getpid())
print('通过进程2获取父进程名称: ', os.getppid())
if __name__ == '__main__':
nums.append('haha')
p1 =Process(target=work1)
p1.start()
# 主进程可以控制子进程的生命周期
p2 =Process(target=work2)
p2.start()
print('这是主进程: ',time.ctime())
print('这是主进程的pid',os.getpid())
print('haha')from multiprocessing import Process
from time import sleep
def run_proc(num1,num2,*args,**kwargs):
result = num1 + num2
for i in args:
result += i
for i in kwargs:
print(i, '的值是:', kwargs[i])
result += kwargs[i]
print('运行结果是: ', result)
sleep(2)
if __name__ == '__main__':
p = Process(target=run_proc, args=(1,2,3,4,5,7), kwargs={'m':20,'n':100})
p.start()
print(p.name)
sleep(1)# -*- coding:utf-8 -*-
from multiprocessing import Process
import os
import time
nums = [11, 22]
def work1():
"""子进程要执行的代码"""
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
for i in range(3):
nums.append(i)
time.sleep(1)
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
def work2():
"""子进程要执行的代码"""
print("in process2 pid=%d ,nums=%s" % (os.getpid(), nums))
if __name__ == '__main__':
p1 = Process(target=work1)
p1.start()
p1.join()
p2 = Process(target=work2)
p2.start()子进程会复制主进程的资源,所以不会影响全局变量
全局变量只有主进程才能修改
进程: 能够完成多任务, 比如 在一台电脑上能够同时运行多个QQ
线程: 能够完成多任务, 比如 一个QQ中的多个聊天窗口
- 进程 是系统进行资源分配和调度的一个独立单位.
- 线程 是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
- 主进程关闭后,子进程依然可以运行
- 一个程序至少有一个进程,一个进程至少有一个线程.
- 线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
- 进程在执行过程中拥有独立的内存单元, 而多个线程共享内存,从而极大地提高了程序的运行效率
- 线程不能够独立执行,必须依存在进程中
- 可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
- 需要频繁创建销毁的优先使用线程; 因为对进程来说,创建和销毁一个进程代价是很大的.
- 线程的切换速度很快, 所以在需要大量计算, 切换频繁时用线程, 还有耗时的操作使用线程可提高应用程序的响应
- 因为对CPU系统的效率使用上线程更占优, 所以所以可能要发展到多机分布的用进程, 多核分布的用线程
- 需要更稳定安全时, 适合选择进程; 需要速度时, 选择线程更好.
Process之间有时需要通信,操作系统提供了很多机制来实现进程间的通信
queue的full() 和 empty()的作用
能够使用qsize()获取队列中消息的个数
# 导入多进程工具包
import multiprocessing
# 创建进程的队列对象
queue = multiprocessing.Queue(4)
# 往队列中放入内容
queue.put(1)
queue.put(2)
queue.put(3)
queue.put(4)
print('取数据前, 队列消息数量',queue.qsize())
value1 = queue.get()
print('取出的数据是: ', value1)
print('取数据后, 队列消息数量',queue.qsize())
print('判断队列是否被填满',queue.full())
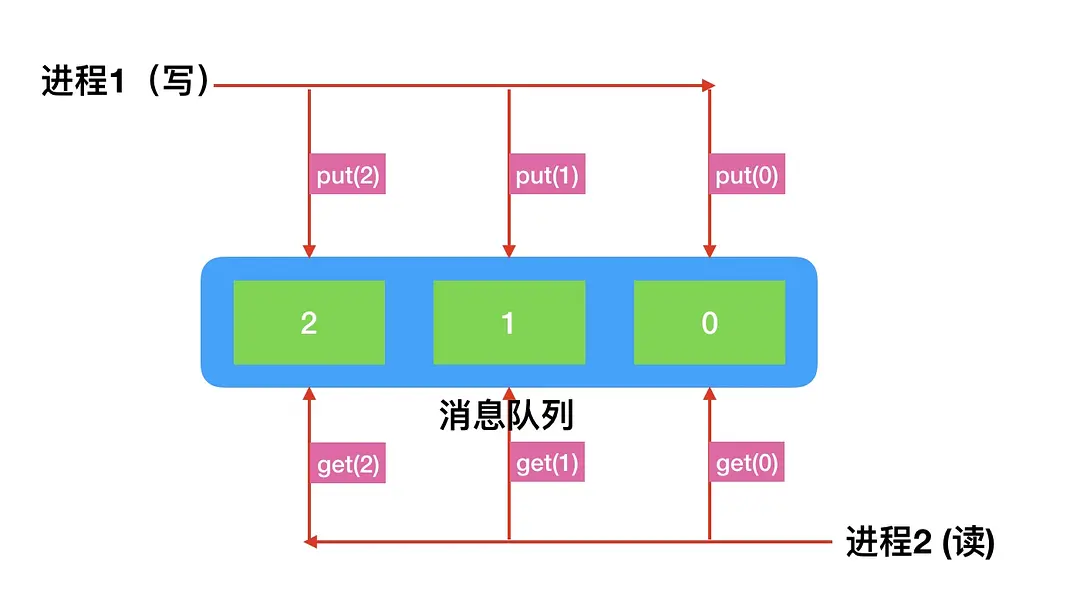
print('判断队列是否为空',queue.empty())queue 队列
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue(队列)本身是一个消息列队程序,首先用一个小实例来演示一下Queue的工作原理:
| 方面 | 描述 |
|---|---|
| queue.full() | 判断队列是否充满 |
| queue.empty() | 判断队列是否为空 |
| queue.qsize() | 返回队列的大致长度 |
| queue.put() | 将对象放入队列 |
| queue.get() | 从队列中取出并返回对象 |
| queue.get_nowait()=queue.get(False) | 仅当有可用对象能够取出是返回(会抛出异常) |
| queue.put_nowait()=queue.put(obj, False) | 仅当有可用反冲槽时才放入对象(会抛出异常 |
from multiprocessing import Queue
q=Queue(3) #初始化一个Queue对象,最多可接收三条put消息
q.put("消息1")
q.put("消息2")
print(q.full()) #False
q.put("消息3")
print(q.full()) #True
#因为消息列队已满下面的try都会抛出异常,第一个try会等待2秒后再抛出异常,第二个Try会立刻抛出异常
try:
q.put("消息4",True,2)
except:
print("消息列队已满,现有消息数量:%s"%q.qsize())
try:
q.put_nowait("消息4")
except:
print("消息列队已满,现有消息数量:%s"%q.qsize())
#推荐的方式,先判断消息列队是否已满,再写入
if not q.full():
q.put_nowait("消息4")
#读取消息时,先判断消息列队是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头);
- Queue.qsize():返回当前队列包含的消息数量;
- Queue.empty():如果队列为空,返回True,反之False ;
- Queue.full():如果队列满了,返回True,反之False;
- Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block默认值为True;
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常;
2)如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常;
- Queue.get_nowait():相当Queue.get(False);
- Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True;
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常;
2)如果block值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常;
- Queue.put_nowait(item):相当Queue.put(item, False);
知道使用queue队列能够实现进程间数据共享
import multiprocessing
import time
# 创建全局队列对象
queue = multiprocessing.Queue(5)
def write_queue():
for i in range(10):
if queue.full():
break
queue.put(i)
print('这是第%d次写入: ' % i , i)
time.sleep(0.5)
def read_queue():
for i in range(10):
if queue.empty():
break
print('这是第%d次读取: ' % i, queue.get())
time.sleep(0.5)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=write_queue)
p2 = multiprocessing.Process(target=read_queue)
p1.start()
# p1.join(timeout=1)
p1.join()
p2.start()
知道 进程池
是一个上下文对象, 使用完成后需要对其进行关闭, 推荐使用 with 实现
创建进程池实例,
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务.
进程池实现效果
请看下面的实例:
from multiprocessing import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d" % (msg,os.getpid()))
# random.random()随机生成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start))
po = Pool(3) # 定义一个进程池,最大进程数3
for i in range(0,10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,))
print("----start----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")multiprocessing.Pool常用函数解析:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
- close():关闭Pool,使其不再接受新的任务;
- terminate():不管任务是否完成,立即终止;
- join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用;
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
下面的实例演示了进程池中的进程如何通信:
# -*- coding:utf-8 -*-
# 修改import中的Queue为Manager
from multiprocessing import Manager,Pool
import os,time
def reader(q):
print("reader启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader从Queue获取到消息:%s" % q.get(True))
def writer(q):
print("writer启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "itcast":
q.put(i)
if __name__=="__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用Manager中的Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())掌握 可迭代对象 和迭代器的区别
理解
for ... in ...循环的本质熟悉 iter 方法 和 next 方法的作用
掌握 自定义 一个
迭代器
迭代是访问集合元素的一种方式,
迭代器是一个可以记住遍历的位置的对象
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束
迭代器只能往前不会后退
迭代器有两个基本的方法:iter(可迭代对象) 和 next(迭代器)。
用iter函数可以获得可迭代对象的迭代器(抽象概念)
next函数 可以获得迭代器数据
我们已经知道可以对list、tuple、str等类型的数据使用for...in...的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代(iterate)。
字符串(string)的本质也是一个集合元素
迭代: 重复反馈
可迭代的(iterable): list, str, range,enumerate,dict, tuple,set
不可迭代的: int ...
- 可遍历对象就是可迭代对象
- 可迭代对象的本质:对象所属的类中包含了__iter__()方法
一个对象所属的类中含有__iter()__ 方法, 该对象就是一个可迭代对象
# 新版本中将用collection.abc 模块导入Iterable
from collections.abc import Iterable
# 使⽤isinstance() 函数检测某个对象是否是⼀个可迭代的对象
class MyClass(object):
# 可迭代对象的本质是,类中是否定义了 __iter__() 方法,返回自身
def __iter__(self):
return self
# 迭代的过程是一直调用self.__next__ = next(self)函数
c1 = MyClass()
# 对象c1不是可迭代对象
result = isinstance(c1, Iterable)
print(result)
就是可以向我们提供一个这样的中间“人”(对象)即迭代器帮助我们对其进行迭代遍历使用。
可迭代对象通过__iter__方法向我们提供一个迭代器,我们在迭代一个可迭代对象的时候,实际上就是先获取该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据.
那么也就是说,一个具备了__iter__方法的对象,就是一个可迭代对象。
迭代对象原理:实际上就是先获取该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据
用来表示一连串数据流的对象。重复调用迭代器的 __next__() 方法(或将其传给内置函数 next()将逐个返回流中的项。当没有数据可用时则将引发 StopIteration] 异常。到这时迭代器对象中的数据项已耗尽,继续调用其 __next__() 方法只会再次引发 StopIteration 异常。
迭代器必须具有 __iter__() 方法用来返回该迭代器对象自身,因此迭代器必定也是可迭代对象,可被用于其他可迭代对象适用的大部分场合。一个显著的例外是那些会多次重复访问迭代项的代码。容器对象(例如 list)在你每次向其传入 iter() 函数或是在 for 循环中使用它时都会产生一个新的迭代器。如果在此情况下你尝试用迭代器则会返回在之前迭代过程中被耗尽的同一迭代器对象,使其看起来就像是一个空容器。
我们分析对可迭代对象进行迭代使用的过程,发现每迭代一次(即在for...in...中每循环一次)都会返回对象中的下一条数据,一直向后读取数据直到迭代了所有数据后结束。那么,在这个过程中就应该有一个“人”去记录每次访问到了第几条数据,以便每次迭代都可以返回下一条数据。我们把这个能帮助我们进行数据迭代的“人”称为迭代器(Iterator)。
可迭代对象通过 iter 方法向我们提供⼀个迭代器,我们在迭代⼀个可迭代对象的时候,实 际上就是先获取该对象提供的⼀个迭代器,然后通过这个迭代器来依次获取对象中的每⼀个数据.
容器对象
容器对象要提供迭代支持,必须定义一个方法:
container.iter()返回一个迭代器对象
迭代器对象
迭代器对象自身需要支持以下两个方法,它们共同组成了 迭代器协议:
iterator.iter() 返回迭代器对象本身。iterator.next() 从容器中返回下一项。
- 我们可以通过iter函数获取这些可迭代对象的迭代器
list、tuple等都是可迭代对象,我们可以通过iter()函数获取这些可迭代对象的迭代器。然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。
iter()函数实际上就是调用了可迭代对象的__iter__方法。
在使用next()函数的时候,调用的就是迭代器对象的__next__方法。所以,我们要想构造一个迭代器,就要实现它的__next__方法。
注意,当我们已经迭代完最后一个数据之后,再次调用next()函数会抛出StopIteration的异常,来告诉我们所有数据都已迭代完成,不用再执行next()函数了
>>> li = [11, 22, 33, 44, 55]
>>> li_iter = iter(li)
>>> next(li_iter)
11
>>> next(li_iter)
22
>>> next(li_iter)
33
>>> next(li_iter)
44
>>> next(li_iter)
55
>>> next(li_iter)
通过上面的分析,我们已经知道,迭代器是用来帮助我们记录每次迭代访问到的位置--类似指针,当我们对迭代器使用next()函数的时候,迭代器会向我们返回它所记录位置的下一个位置的数据。
实际上,在使用next()函数的时候,调用的就是迭代器对象的__next__方法。所以,我们要想构造一个迭代器,就要实现它的__next__方法。
但这还不够,python要求迭代器本身也是可迭代的,所以我们还要为迭代器实现__iter__方法,而__iter__方法要返回一个迭代器,迭代器自身正是一个迭代器,所以迭代器的__iter__方法返回自身即可。
一个实现了__iter__方法和__next__方法的对象,就是迭代器。
可迭代对象 具备 __iter__方法
迭代器:让可迭代对象具备__next__方法和__iter__方法
iter()函数可以将可迭代对象 转换成迭代器
for item in Iterable 循环的本质就是
先通过iter()函数获取可迭代对象Iterable的迭代器,
然后对获取到的迭代器不断调用next()方法来获取下一个值
并将其赋值给item,
当遇到StopIteration的异常后循环结束。
我们发现迭代器最核心的功能就是可以通过next()函数的调用来返回下一个数据值。
如果每次返回的数据值不是在一个已有的数据集合中读取的,而是通过程序按照一定的规律计算生成的,那么也就意味着可以不用再依赖一个已有的数据集合,也就是说不用再将所有要迭代的数据都一次性缓存下来供后续依次读取,这样可以节省大量的存储(内存)空间。
Asa:迭代器是一个标准模板,是一个存储特定规律数据的容器,调用该数据的方法是用next()方法调用
Asa:按照规律存储数据,每个数据都有固定的地址以供访问,数据的存储是虚拟的,只用在调用时才会通过计算生成数据,因此会极大的节省数据空间
举个例子,比如,数学中有个著名的斐波拉契数列(Fibonacci),数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
现在我们想要通过for...in...循环来遍历迭代斐波那契数列中的前n个数。那么这个斐波那契数列我们就可以用迭代器来实现,每次迭代都通过数学计算来生成下一个数。
除了for循环能接收可迭代对象,list、tuple等也能接收。
- 必须含有
__iter__() - 必须含有
__next__()
class MyIterator:
def __iter__(self):
pass
def __next__(self):
pass数学中有个著名的斐波拉契数列(Fibonacci),数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
目标: 自定义一个列表(对象)
理解底层迭代原理 自定义数据结构
-
自定义列表需求:
- 使其能够使用for in 遍历
- 能够在其中添加数据
- 构造方法(init方法)
能够用两种方法创建生成器
利用迭代器,我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。生成器是一类特殊的迭代器。
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
调用一个生成器函数,返回的是一个迭代器对象。
要创建一个生成器,有很多种方法。第一种方法很简单,只要把一个列表生成式的 [ ] 改成 ( )
L = [ x*2 for x in range(5)]
G = ( x*2 for x in range(5))建 L 和 G 的区别仅在于最外层的 [ ] 和 ( ) , L 是一个列表,而 G 是一个生成器。我们可以直接打印出列表L的每一个元素,而对于生成器G,我们可以按照迭代器的使用方法来使用,即可以通过next()函数、for循环、list()等方法使用。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的 for 循环无法实现的时候,还可以用函数来实现。
def fibonacci(n):
a = 0
b = 1
current_index = 0
while current_index < n:
result = a
a, b = b, a + b
current_index += 1
yield result
for i in fibonacci(100):
print(i)注意,在用迭代器实现的方式中,我们要借助几个变量(n、current、num1、num2)来保存迭代的状态。现在我们用生成器来实现一下。
在使用生成器实现的方式中,我们将原本在迭代器__next__方法中实现的基本逻辑放到一个函数中来实现,但是将每次迭代返回数值的return换成了yield,此时新定义的函数便不再是函数,而是一个生成器了。简单来说:只要在def中有yield关键字的函数就称为 生成器
此时按照调用函数的方式( 案例中为F = fib(5) )使用生成器就不再是执行函数体了,而是会返回一个生成器对象( 案例中为F ),然后就可以按照使用迭代器的方式来使用生成器了。
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
产生 产生 迭代器
类似于返回 return
使用了yield关键字的函数不再是函数, 而是生成器.
使用了yield的函数就是生成器
yield关键字有两点作用:
- 保存当前运行状态(断点), 然后暂停执行, 即将生成器(函数)挂起
- 将yield关键字后面表达式的值作为返回值返回, 此时可以理解为起到了return的作用
因为是一类特殊的的迭代器 所以具备可迭代特性 用法和迭代器差不多 使用next()函数
- 创建迭代器的简单而强大的工具. 他们写起来就像正规的函数, 只是在需要返回数据的时候使用yield语句. 每次next()被调用时, 生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有数据值)
- 生成器和迭代器都是python中的特有概念
- iter()函数会返回一个迭代器对象 iter()函数 配合yield 会返回迭代器
- 生成器能做到迭代器能做到的所有事, 而且因为自动创建了iter()和 next()方法, 生成器显得特别简介
生成器中不要使用return
我们除了可以使用next()函数来唤醒生成器继续执行外,还可以使用send()函数来唤醒执行。使用send()函数的一个好处是可以在唤醒的同时向断点处传入一个附加数据。
例子:执行到yield时,gen函数作用暂时保存,返回i的值; temp接收下次c.send("python"),send发送过来的值,c.next()等价c.send(None)
- 使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器)
- yield关键字有两点作用:
- 保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起
- 将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用
- 可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数)
- Python3中的生成器可以使用return返回最终运行的返回值,而Python2中的生成器不允许使用return返回一个返回值(即可以使用return从生成器中退出,但return后不能有任何表达式)。
async/await实现协程
实现多任务的一种方法
协程(coroutine)是一个重要的编程技术,在许多编程语言中都有体现。
从技术角度来说: '协程就是你可以暂停执行的函数'. 如果你把它理解成'像生成器一样', 那么你就想对了
线程和进程的操作是由程序触发系统接口, 最后的执行者是系统; 协程的操作则是程序员.
协程存在的意义: 对于多线程应用, CPU通过切片的方式来切换线程间的执行, 线程切换时需要耗时(保存状态,下次继续). 协程则只是用一个线程(单线程), 在一个线程中规定某个代码块执行顺序.
协程的适用场景: 当程序中存在大量不需要CPU的操作时(IO), 适用于协程;
协程 是python个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的资源)。 为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机, 我们可以把一个协程 切换到另一个协程。 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定
在实现多任务时, 线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。
操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。
所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
import time
def work1():
while True:
print("----work1---")
yield
time.sleep(0.5)
def work2():
while True:
print("----work2---")
yield
time.sleep(0.5)
def main():
w1 = work1()
w2 = work2()
while True:
next(w1)
next(w2)
if __name__ == "__main__":
main()协程能搞定 延时性操作不能同时进行的情况
- 干活的是线程, 代码的封装的是进程,看到执行的是进程
- 进程是系统资源分配的单位
- 线程是操作系统调度的单位
- 进程切换需要的资源很最大,效率很低
- 线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
- 协程切换任务资源很小,效率高
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
异步编程实现的目标是 解决单线程阻塞的问题 来提升软件的性能 线程 是系统的最小调度单位 运行时是没办法(干预的)
异步调用的关键点在于分流和回调执行起点。分流就是在当前代码位置,将一部分代码加入到条件达成后未来的回调执行流中,而另一部分代码则在当前程序流继续执行。回调执行起点通常为一个条件达成后来自操作系统的通知或者程序内部的消息(事件)。该事件会出发一个回调执行起点方法,去逆向执行回调流中的各个方法。
asyncio 是用来编写 并发 代码的库,使用 async/await 语法。适用于IO密集型网络编程, 处理高并发,弥补GIL不能发挥多核的优势
PEP 3156 是Python 3.4 中引入异步I/O框架asyncio 的一个提案,提供了基于协程做异步I/O编写单线程并发代码的基础设施。随后在PEP492 中引入了 async/await语法 以及 PEP380中的yield from 语法,自此,Python有了原生的协程支持,不再依赖外部第三方库。
Python有三中主要的并发编程方式: 多线程, 多进程和异步编程.
- 任务划分, 确保任务之间的数据依赖最小化, 避免频繁的锁竞争
- 数据共享问题
- 使用进程池/线程池技术来管理线程池和进程池. 这些池可以帮助你有效地分配和管理并发任务, 避免创建和销毁线程或进程的开销.
- 优雅关闭: 线程与进程通常使用
join()方法等待其完成, asyncio则使用await来等待任务结束.
多线程: 适合I/O密集型任务(IO-bound), 但因为GIL的存在, 线程再CPU密集型任务中不能充分利用多核CPU.
多进程: 适合CPU密集型任务(CPU-bound), 可以利用多核CPU, 避免GIL限制.
异步编程: 适合需要高并发处理的I/O密集型任务, 如大量的网络请求或事件驱动应用
| 多线程 | ||
| 多进程 | ||
| 异步编程 |
异步IO库
- 主要的并发处理方式
- 协程
- 任务: 协程的具体执行实例
- asyncio.create_task
- loop.create_task
- 事件循环
Asynchronous programming is different from classic “sequential” programming.
Note
经典的顺序编程假设只有一个控制流, 不会存在让出控制权, 并发执行的情形. 所有相对简单
aws: awaitables 一组可等待对象
通过asyncio.run执行一个简单的谢谢
并发性和多线程¶:
事件循环在线程中运行(通常是主线程),并在其线程中执行所有回调和任务。当一个任务在事件循环中运行时,没有其他任务可以在同一个线程中运行。当一个任务执行一个 await 表达式时,正在运行的任务被挂起,事件循环执行下一个任务。
import asyncio
async def hello_world():
print("Hello")
await asyncio.sleep(1) # 模拟 I/O 操作
print("World")
# 运行事件循环
asyncio.run(hello_world())- Future对象就是一个延迟执行对象, 当该对象执行完毕后再通过result(返回结果)等方式将控制流交回到可等待对象
- 用于编写回调式代码, 当Future对象返回结果后继续执行某件事情
import asyncio
import time
async def task1():
print(f"Task 1 started at {time.strftime('%X')}")
await asyncio.sleep(2)
print(f"Task 1 finished at {time.strftime('%X')}")
async def task2():
print(f"Task 2 started at {time.strftime('%X')}")
await asyncio.sleep(1)
print(f"Task 2 finished at {time.strftime('%X')}")
# 同时运行两个任务
async def main():
await asyncio.gather(task1(), task2())
asyncio.run(main())import asyncio
async def producer(queue):
for i in range(5):
print(f"producer producing {i}")
await queue.put(i)
await asyncio.sleep(1)
async def consumer(queue):
while True:
item = await queue.get()
print(f"consumer consuming {item}")
queue.task_done()
async def main():
queue = asyncio.Queue(maxsize=10)
await asyncio.gather(producer(queue), consumer(queue))
asyncio.run(main())异步和并发是两个常见的计算机科学概念,它们经常被混淆。异步和并发都涉及多个任务同时执行,但它们之间存在一些关键的区别。
异步
异步是指任务之间不相互等待。这意味着一个任务可以开始执行,而另一个任务还没有完成。异步编程通常使用回调函数来处理任务的完成。
并发
并发是指多个任务在同一时间段内执行。这意味着多个任务可能在同一时刻使用相同的资源。并发编程通常使用多线程或多进程来实现。
异步和并发的区别
异步和并发的主要区别在于等待。在异步编程中,一个任务可以开始执行,而另一个任务还没有完成。这意味着主线程可以继续执行其他任务,而无需等待第一个任务完成。在并发编程中,多个任务在同一时间段内执行。这意味着多个任务可能在同一时刻使用相同的资源。
异步和并发的应用
异步和并发在许多领域都有应用,包括:
- 网络编程:异步编程可以用于处理网络请求,而无需阻塞主线程。
- 用户界面:异步编程可以用于更新用户界面,而无需等待昂贵的计算完成。
- 数据库访问:异步编程可以用于访问数据库,而无需阻塞主线程。
- 多媒体处理:异步编程可以用于处理多媒体数据,而无需等待数据加载完成。
异步和并发的选择
在选择异步或并发时,需要考虑以下因素:
- 任务的性质:如果任务是阻塞的,则需要使用异步编程。
- 资源的使用:如果任务需要使用大量资源,则需要使用并发编程。
- 性能要求:如果需要提高性能,则可以考虑使用异步或并发。
总结
异步和并发是两个重要的计算机科学概念。它们可以用于提高性能和效率。在选择异步或并发时,需要考虑任务的性质、资源的使用和性能要求。
同步(Sync): 完成事务的逻辑,先执行第一个事务,如果阻塞了,会一直等待,直到这个事务完成,再执行第二个事务,顺序执行
异步(Async): 在处理调用这个事务的之后,不会等待这个事务的处理结果,直接处理第二个事务去了,通过状态、通知、回调来通知调用者处理结果。
参考引用
高层级 API
低层级 API
指南与教程
asyncio 被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等。
asyncio 往往是构建 IO 密集型和高层级 结构化 网络代码的最佳选择。
asyncio 提供一组 高层级 API 用于:
- 并发地 运行 Python 协程 并对其执行过程实现完全控制;
- 执行 网络 IO 和 IPC;
- 控制 子进程;
- 通过 队列 实现分布式任务;
- 同步 并发代码;
此外,还有一些 低层级 API 以支持 库和框架的开发者 实现:
- 创建和管理 事件循环,以提供异步 API 用于
网络化, 运行子进程,处理OS 信号等等; - 使用 transports 实现高效率协议;
- 通过 async/await 语法 桥接 基于回调的库和代码。
并发用单个处理器, 将一个时间段分为N个时间片, 让其中一个时间片来实现其中一个程序, 由操作系统轮询时间片来实现同一个时间段内同时并发多个程序的执行
协程通过 async/await 语法进行声明,是编写异步应用的推荐方式。例如,以下代码段 (需要 Python 3.7+) 打印 "hello",等待 1 秒,然后打印 "world":
import asyncio
async def main():
print("hello")
await asyncio.sleep(1)
print("world!")
asyncio.run(main())hello
world
**注意: **简单地调用一个协程并不会将其加入执行日程, 而是返回一个协程对象
>>> main()
<coroutine object main at 0x1053bb7c8>
要真正运行一个协程,asyncio 提供了三种主要机制:
asyncio.run()函数用来运行最高层级的入口点 "main()" 函数- 等待一个协程。以下代码段会在等待 1 秒后打印 "hello",然后 再次 等待 2 秒后打印 "world":
import asyncio
import time
async def say_after(delay: float, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at{time.strftime('%X')}")
await say_after(1,'hello') # 其实就是可阻塞对象
await say_after(2,'world')
print(f"finished at{time.strftime('%X')}")
# 单线程异步, 作为单线程在运行
if __name__ == '__main__':
asyncio.run(main())started at14:59:51
hello
world
finished at14:59:54
asyncio.create_task()函数用来并发运行作为 asyncio任务的多个协程。 让我们修改以上示例,并发 运行两个say_after协程:
import asyncio
import time
async def say_after(delay: float, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at{time.strftime('%X')}")
task1 = asyncio.create_task(say_after(1,'hello'))
task2 = asyncio.create_task(say_after(2,'world'))
await task1 # 其实就是可阻塞对象
await task2
print(f"finished at{time.strftime('%X')}")
# 单线程异步, 作为单线程在运行
if __name__ == '__main__':
asyncio.run(main())注意, 预期的输出显示代码段的运行时间比之前快了1秒
started at15:05:43
hello
world
finished at15:05:45
如果一个对象可以在 await 语句中使用,那么它就是 可等待 对象。许多 asyncio API 都被设计为接受可等待对象。
可等待 对象有三种主要类型: 协程, 任务 和 Future.
Python 协程属于 可等待 对象,因此可以在其他协程中被等待:
import asyncio
async def nested():
return 42
async def main():
# 如果我们仅仅是调用nested()什么都不会发生
# 协程对象被创建但是不是可等待的
# 因此它将不会运行
await nested()
print(await nested())
asyncio.run(main())**重要:**在本文档中 协程 可以来表示两个紧密相关的概念:
- 协程函数: 定义形式为
async def的函数; - 协程对象: 调用 协程函数 所返回的对象。
asyncio 也支持旧式的 基于生成器的 协程。
任务 被用来设置日程(协程的子任务)以便 并发 执行协程。
当一个协程通过 asyncio.create_task() 等函数被打包为一个 任务,该协程将自动排入日程准备立即运行:
import asyncio
async def nested():
# await asyncio.sleep(1)
print('Ting')
return 42
async def main():
task = asyncio.create_task(nested())
await task
asyncio.run(nested())Future 是一种特殊的 低层级 可等待对象,表示一个异步操作的 最终结果。
当一个 Future 对象 被等待,这意味着协程将保持等待直到该 Future 对象在其他地方操作完毕。
在 asyncio 中需要 Future 对象以便允许通过 async/await 使用基于回调的代码。
通常情况下 没有必要 在应用层级的代码中创建 Future 对象。
Future 对象有时会由库和某些 asyncio API 暴露给用户,用作可等待对象:
import asyncio
async def main():
await function_that_returns_a_future_object()
# this is also valid:
await asyncio.gather(
function_that_returns_a_future_object(),
some_python_coroutine()
)
一个很好的返回对象的低层级函数的示例是 loop.run_in_executor()。
属性:关键字
作用: 用async/await 语法对函数进行声明, 表示该函数为协程函数
概念:
async def func():
passselect+ 回调+事件循环
asyncio.run(coro, *, debug=False)
此函数运行传入的协程,负责管理 asyncio 事件循环并 完结异步生成器。
当有其他 asyncio 事件循环在同一线程中运行时,此函数不能被调用。
如果 debug 为 True,事件循环将以调试模式运行。
此函数总是会创建一个新的事件循环并在结束时关闭之。它应当被用作 asyncio 程序的主入口点,理想情况下应当只被调用一次。
重要: 此函数是在 Python 3.7 中加入 asyncio 模块,处于 暂定基准状态。
asyncio.create_task(coro)
将 coro 协程 打包为一个 Task 排入日程准备执行。返回 Task 对象。
该任务会在 get_running_loop() 返回的循环中执行,如果当前线程没有在运行的循环则会引发 RuntimeError。
async def coro():
pass
task = asyncio.create_task(coro())
coroutine asyncio.sleep(delay, result=None, *, loop=None)
阻塞 delay 指定的秒数。
如果指定了 result,则当协程完成时将其返回给调用者。
作用:sleep() 总是会挂起当前任务,以允许其他任务运行。
loop 参数已弃用,计划在 Python 3.10 中移除。
以下协程示例运行 5 秒,每秒显示一次当前日期:
import asyncio
import datetime
async def display_date():
loop = asyncio.get_running_loop()
end_time = loop.time() + 5.0
while True:
print(datetime.datetime.now())
if (loop.time() + 1.0) >= end_time:
break
await asyncio.sleep(1)
asyncio.run(display_date())awaitable asyncio.gather(*aws, oop=None, return_exceptions=False)
并发 运行 aws 序列中的 可等待对象。
如果 aws 中的某个可等待对象为协程,它将自动作为一个任务加入日程。
如果所有可等待对象都成功完成,结果将是一个由所有返回值聚合而成的列表。结果值的顺序与 aws 中可等待对象的顺序一致。
如果 return_exceptions 为 False (默认),所引发的首个异常会立即传播给等待 gather() 的任务。aws 序列中的其他可等待对象 不会被取消 并将继续运行。
如果 return_exceptions 为 True,异常会和成功的结果一样处理,并聚合至结果列表。
如果 gather() 被取消,所有被提交 (尚未完成) 的可等待对象也会 被取消。
如果 aws 序列中的任一 Task 或 Future 对象 被取消,它将被当作引发了 CancelledError 一样处理 -- 在此情况下 gather() 调用 不会被取消。这是为了防止一个已提交的 Task/Future 被取消导致其他 Tasks/Future 也被取消。
在 3.7 版更改: 如果 gather 本身被取消,则无论 return_exceptions 取值为何,消息都会被传播。
Tip
消息队列可以实现解耦、削峰和异步处理等功能。一些常见使用场景有:异步处理:可以提高系统的响应速度和吞吐量。解耦:可以降低模块之间的耦合度,提高系统的可维护性和可扩展性。削峰:将请求放入消息队列中,可以平滑处理请求峰值,避免系统崩溃。任务调度:将任务放入消息队列中,可以实现任务的异步调度和分布式执行。通知和推送:将通知和推送消息放入消息队列中,可以提高通知和推送的效率和可靠性。数据同步:将数据同步消息放入消息队列中,可以实现数据的异步同步和分布式处理。需要注意的是,消息队列并不是万能的解决方案,需要根据具体的应用场景和需求来选择合适的消息队列和配置参数,以确保系统的性能和可靠性。同时,消息队列的使用也需要考虑数据一致性、消息丢失和重复消费等问题,需要进行充分的测试和评估,以确保系统的正确性和可靠性。
Note
AI提问:消息队列异步任务处理时, 主调端如何获得任务处理状态, 有哪些方式来实现当任务处理完成后, 主调能够知晓
在消息队列(Message Queue, MQ)用于异步任务处理的场景中,主调端通常需要知晓任务的处理状态,包括是否成功完成、失败的原因等。实现这种机制的方法有多种,主要取决于所使用的消息队列系统、任务的性质以及系统的设计。以下是几种常见的实现方式:
- 机制:任务处理器(Worker)在处理任务时,会在数据库或其他存储系统中更新任务的状态。主调端可以通过查询这些状态来获得任务的处理情况。
- 优点:简单直观,容易实现。
- 缺点:需要轮询查询状态,可能会导致延迟和资源浪费。
- 机制:任务完成后,处理器调用主调端提供的回调接口(API)来通知任务完成的结果。
- 优点:实时性好,主调端能够即时获得任务状态。
- 缺点:需要主调端暴露可访问的回调接口,可能增加系统的复杂性和安全考虑。
- 机制:使用单独的消息队列来存储任务的结果和状态。任务处理完成后,处理器将结果发布到这个队列中,而主调端订阅这个队列来获取任务状态。
- 优点:解耦性好,支持分布式处理,实时性较好。
- 缺点:需要维护额外的消息队列,可能增加系统的复杂性。
- 机制:基于事件驱动架构,任务的各种状态变更(如开始处理、完成、失败)都作为事件发布。主调端通过监听这些事件来获得任务状态。
- 优点:高度解耦,灵活性高,易于扩展。
- 缺点:实现复杂,对事件系统的依赖较强。
- 机制:利用如 Celery 这样的任务队列管理框架,它们内置了任务状态跟踪和结果存储的功能。主调端可以通过查询这些框架提供的接口来获得任务状态。
- 优点:功能强大,支持丰富的任务管理和监控功能,易于使用。
- 缺点:引入额外的依赖和学习成本。
- 机制:使用 Websocket 或 SSE 在客户端和服务器之间建立一个持久的连接,服务器可以通过这个连接实时推送任务状态给客户端。
- 优点:实时性非常好,用户体验佳。
- 缺点:实现相对复杂,对网络环境有一定要求。
选择哪种机制主要取决于应用的具体需求、实现的难易程度以及系统的可维护性。在实际应用中,也可以根据需要结合使用多种机制。
- 机制:任务处理器(Worker)在处理任务时,会在数据库或其他存储系统中更新任务的状态。主调端可以通过查询这些状态来获得任务的处理情况。
- 优点:简单直观,容易实现。
- 缺点:需要轮询查询状态,可能会导致延迟和资源浪费。
让程序以服务的方式运行的方法
- time.sleep
- I/O
- Lock
- Queue.get()为空时
- await 语句
- socket.recv , socktet.accpet
- Event
- process.join
- threading.join
- Future.result()
- shutdown(wait=True)
- concurrent.futures.as_completed
- concurrent.futures.wait
- subprocess.run
- subprocess.wait