
This GitHub organization hosts the collective efforts, code, and resources for our team's participation in the 2025 EEG Foundation Challenge: From Cross-Task to Cross-Subject EEG Decoding, accepted to the NeurIPS 2025 Competition Track.
The competition is built around the HBN-EEG dataset (~3,000+ participants, 6 tasks) and is run as a code-submission challenge on Codabench.
- Overall rank:
18 / 1,183teams (final leaderboard) - Final scores (Codabench metric):
- Overall:
0.98008 - Challenge 1 – Cross-Task Transfer Learning:
0.94021 - Challenge 2 – Externalizing Factor Prediction:
0.99717
- Overall:
- There were 1,183 teams/participants and more than 8,000 submissions on the open-source platform Codabench, making this EEG challenge one of the largest competitions ever hosted on the platform.
This organization documents the models, experiments, and engineering work that led to these results.
The final execution-phase design (official website + starter kit) defines two independent challenges, each with its own ranking and awards.
| Challenge | Goal | Target | Evaluation Metric |
|---|---|---|---|
| 1. Cross-Task Transfer Learning | Learn EEG representations that transfer from multiple (mainly passive) tasks to an active task. | Trial-wise response time (RT) in the Contrast Change Detection (CCD) task. | Normalized RMSE (NRMSE) over RT. |
| 2. Externalizing Factor Prediction | Learn subject-invariant EEG representations that predict a dimensional psychopathology trait. | Subject-level externalizing factor score derived from CBCL (bifactor model). | Normalized RMSE (NRMSE) over externalizing scores. |
Key points:
-
Challenge 1
- Input: CCD EEG epochs, with optional pretraining on all other HBN-EEG tasks or external EEG datasets.
- Output: Continuous response time for each CCD trial.
- Correct/incorrect classifications are not evaluated separately; only RT regression is scored.
-
Challenge 2
- Input: EEG from all six HBN-EEG tasks (passive + active) is encouraged at training time.
- Output: A single externalizing score per subject.
- While the dataset includes p-factor, internalizing, and attention, these are not leaderboard targets in the execution phase; they may be used as auxiliary signals, but only externalizing is evaluated.
All repositories in this organization are aligned with the official competition design above.
| Repository | Role |
|---|---|
| Challenge1 | Models and pipelines for Challenge 1 (CCD response-time regression with cross-task/self-supervised pretraining). |
| Challenge2 | Models and pipelines for Challenge 2 (subject-invariant externalizing prediction using multi-task EEG). |
| startkit | Our working fork / notebookified version of the official starter kit, adapted for rapid prototyping, ablations, and local scoring. |
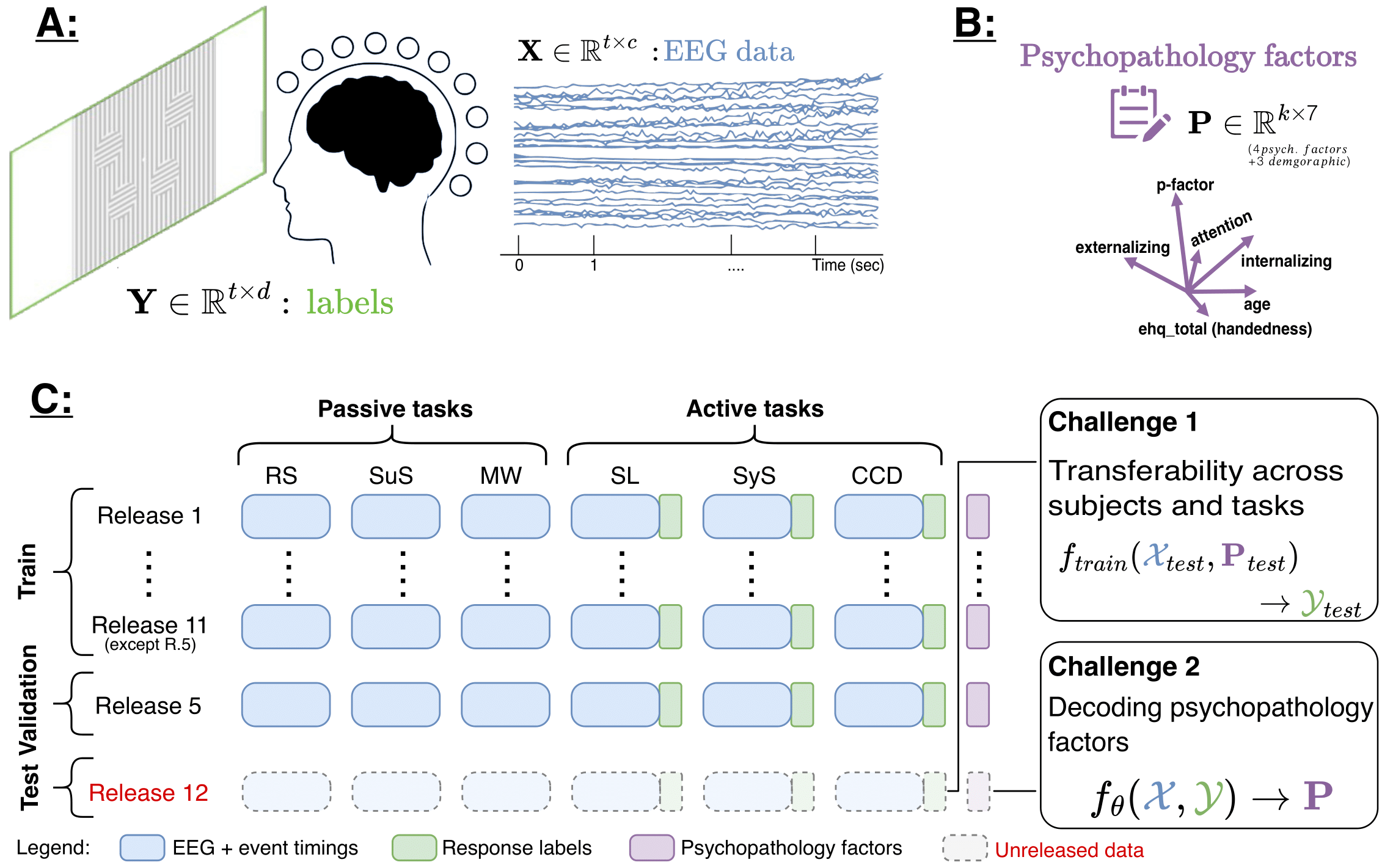
We rely on the HBN-EEG dataset, made FAIR via the official HBN-EEG preprocessing pipeline.
- Participants: 3,000+ children and young adults.
- Recording setup: 128-channel EEG, BIDS-compliant.
- Tasks:
- Passive
- Resting State (RS)
- Surround Suppression (SuS)
- Movie Watching (MW: Despicable Me, Diary of a Wimpy Kid, Fun with Fractals, The Present)
- Active
- Contrast Change Detection (CCD)
- Sequence Learning (SL, 6- and 8-target variants)
- Symbol Search (SyS)
- Passive
For the competition, all EEG has been standardized as:
- Sampling rate: 100 Hz (after 0.5–50 Hz band-pass filtering).
- Formats: BDF (officially used by the starter kit) and SET; both remain BIDS-compatible.
- Release naming:
R{release_number}_L100_(mini)_(bdf), where:minireleases (20 subjects per release) are intended for exploration/warm-up.fullreleases contain the complete dataset for each task and are intended for main-phase training and evaluation.
Data is distributed via AWS S3, SCCN download server (ZIP), and Google Drive, matching the official HBN-EEG / EEGDash layout.
-
Challenge 1 – Response Time Regression
- Trial-wise response times are derived from CCD behavioral logs and aligned to EEG using the official event structure.
- Models are trained to predict RT from CCD EEG; scoring ignores trial correctness and uses only the RT values.
-
Challenge 2 – Externalizing Factor
- Subject-level labels come from the externalizing dimension of the CBCL-derived bifactor model.
- Other psychopathology dimensions (
p-factor,internalizing,attention) remain available in the dataset but are not evaluated; they can be used for multi-task learning, representation analysis, or auxiliary loss design.
Condensed from the official Rules:
- All official evaluation uses the 100 Hz downsampled, 0.5–50 Hz filtered datasets.
- External pretraining is allowed and encouraged, including:
- Other HBN-EEG tasks,
- Other public EEG datasets,
- Existing EEG foundation models.
- Participants may use pretrained/foundation models, but must document which models and how they were adapted.
- This is a code-submission competition; organizers run code inside a standardized environment.
- Resource constraint: Final inference must fit on one GPU with 20 GB of VRAM.
- Related members of the organizing team may participate but are not eligible for prizes.
- The original arXiv preprint describes the initial design (Transfer vs Psychopathology factor challenges), while the website + starter kit define the final execution-phase rules (e.g., externalizing-only Challenge 2, independent rankings).
Team members should be familiar with the following official resources:
- Competition Website: https://eeg2025.github.io
- Codabench Competition Page: https://www.codabench.org/competitions/9975/
- Official GitHub Organization: https://github.com/eeg2025
- Official Starter Kit: https://github.com/eeg2025/startkit
- Challenge Paper (preprint): https://arxiv.org/abs/2506.19141
- HBN-EEG Dataset Page: https://neuromechanist.github.io/HBN_EEG
This organization serves as our internal hub to:
- Explore self-supervised and foundation-model-based pretraining across HBN-EEG tasks and external datasets.
- Study cross-task transfer for CCD response-time prediction (Challenge 1).
- Build and evaluate subject-invariant representations for externalizing prediction (Challenge 2).
- Track experiments, ablations, and final Codabench submission pipelines in a reproducible way.
Contributions, issue reports, and experiment notes within each repository should follow the templates and coding conventions documented there.